Custom CSS Classes :
Revision marks [revision] :
normal text
original text [citation]
=>
replacement text [proposal]
Authors :
Gerard's comments [gerard]
Laurent's comments [laurent]
Rick's comments [rick]
Patrizia's comments [patrizia]
Herve's comments [rv]
In this note we propose that the IVOA develops a standard protocol for storing and discovering
simulations⇒simulation products.
We will call this protocol the Simulation Database and use further the SimDB acronym .
Implementations of the SimDB will allow users to query for results of simulations in quite some detail and will provide
links to services for accessing these simulation products.
The results presented in this note, which form the core of the proposed standard, are one half of a concerted effort of the Theory Interest Group (TIG)
that originally went by the name Simple Numerical Access Protocol (SNAP), and is now split up in two parts.
The second part defines protocols for accessing the the simulations⇒simulation data products themselves. This part will be written up in a separate Note
(Gheller, Wagner et al, in preparation), under the name Simulation Data Access Protocol and the SimDAP acronym.
The current proposal is built around a UML data model describing simulations (derived from the simulation domain model), a representation (mapping) of this model as a relational
database schema and a mapping to an XML schema.
We propose the relational schema to be the outer facade of a SimDB-TAP implementation which is to be queried using
ADQL @@ TODO update the ADQL link to later versions @@
The XML schema provides type definitions from
which a machine readable serialisations of the model may be constructed. The schema also defines root elements for documents
describing SimDB-resources. The SimDB should return such documents for identified SimDB-Resources upon request, as an
alternative to the tabular (VOTable) results of ADQL queries.
In case updates are supported by a SimDB implementation, such documents may be sent
This Note describes use cases and⇒, requirements and the approach we have taken to define a specification
that and current state of the results. ???
We feel that the results are sufficiently far evolved that they can start following the formal IVOA standardisation track.
To this end it could be turned over to one of the existing working groups. If that is the decisions we feel
that the data modelling WG is closest to its scope, but there exist very strong links to Registry, Semantics, ADQL
and DAL as well. One might argue that a targeted WG for this effort alone might be as appropriate.
We leave the decision about this to the IVOA exec.
This is a Note. The first release of this document was 2008 April 19.
The current version was edited 2008 May 20.
This is an IVOA Note expressing suggestions from and opinions of the authors.
It is intended to share best practices, possible approaches, or other perspectives on interoperability with the Virtual Observatory.
It should not be referenced or otherwise interpreted as a standard specification.
A list of
current IVOA Recommendations and other technical documents can be found at http://www.ivoa.net/Documents/.
We thank various persons for useful discussions in the course of this work. First the participants of the
Feb 2006 theory
workshop in Cambridge, UK, where this work was started. Second the participants of the
April 2007 SNAP workshop in
Garching, Germany, where the design started taking shape. Then we want to thank particularly the following persons
for useful discussions and feedback: Jeremy Blaizot, Klaus Dolag, Ray Plante, Volker Springel. We finally want to thank
participants to the theory sessions in the interoperability meetings in Victoria, Moscow, Beijing and Cambridge where parts
of this work was discussed.
@@ TODO Modify this text, which was originally an email to be sent to THEORY, TCG, DM, maybe EXEC @@
We propose to derive two WG projects from what was so far the
SNAP project of the theory interest group: SimDB and SimDAP.
In this note we discuss the first of these, SimDB, in some detail.
Simulation Database (SimDB)
We propose to developa standard specification project, called the "Simulation Database" (SimDB).
It is based on the description+discovery part of the old
SNAP project. Its normative deliverables are
- A logical data model for describing simulations.
Following SNAP we keep concentrating
on 3+1D simulations, with which we mean simulations modelling a
space-time sub-volume of the universe OF ANY SIZE, so not only large
scale structure, galaxy clusters, but everything down to asteroid collisions etc.
As the model describes simulations, it may be called a meta-data model.
It will be a logical model in the sense of standard data modelling approaches @@TODO add some references@@,
and is based on an analysis, or domain model which is presented but not normative.
The logical model is presented in fully detailed and documented UML2, serialised
to XMI 2.1, created using the MagicDraw 12.1 Community edition tool.
The data model is using a small subset of UML2 and has some UML profile
extensions added. Together this can be seen as a domain specific language,
and this can be formalised in a UML Profile. We will propose using such a profile
to the DM working group as a general approach for DM efforts.
- A query protocol based on the logical model.
We propose this to have at least an ADQL version.
To this end we will provide a relational mapping.
This physical model is completely derived from the SimDB logical model using rules
implemented as a pipe-line of XSLT2 scripts working on the XMI representation of
the UML. The scripts will produce relational database DDL scripts defining the
database schema. That schema itself is not normative, instead we will define the
replies to TAP metadata queries. We provide implementation scenarios in the text below,
for the case of someone using the results from this project completely and for the
case of someone implementing a SimDB on top of a legacy database.
- a messaging format for sending instances of the various components
in the data model around.
This format will be based on a number of XML
schema documents (XSDs), one of which contains the root elements defining valid SimDB resources.
This requires a mapping from the UML to XSD.
This mapping will take the form of one or more XSLT documents.
- An IVOA working draft document describing these components.
This will be based on the current document.
We introduce some non-normative solutions that can be taken over for generic
data models (this is ofcourse also true for the UML/XMI+XSLT approach for the
normative standards).
- The XSLT scripts we propose above do not work on the XMI itself, but on
an intermediate representation of the UML data model. This is an XML dialect
based on a schema we define and which captures the UML profile more directly.
XMI is very generic and rather cumbersome to work with. The representation of
the UML in our intermediate XML form is much more readable and XSLT based on it
is much simpler. It also allows easier adaptation to future modifications in UML,
or to tools whose XMI representation is different from the standard. We only need
to update the XMI->Intermediate XSLT transformation scripts. Not the more complex
transformations to the other official representations.
We will propose a similar approach to the DM WG.
- We will provide XMI->Java+JPA+JAXB transformation scripts in XSLT (properly, intermediate->Java).
These scripts generate Java classes corresponding to the types (Class, DataType, Enumeration)
in UML. These classes are annotated with Java Persistence Architecture (JPA)
and Java Architecture for XML Binding (JAXB) attributes to assist in the transformation
between relational database and XML representations.
Similar scripts can be written for C#. C# allows the same annotations as Java 5 supports
already for longer. For persistence we will likely use Linq, which seems similar to JPA.
- We propose an approach for including application specific and legacy simulation databases
in this framework. This approach follows the "global-as-view" approach to information
integration (see for example http://www.deg.byu.edu/papers/PODS.integration.pdf;
Leonid Kalinichenko from the RVO is an expert in this field).
Implementors with an existing relational database schema may be able to define database
views which implement the relational representatiopn of the SimDB data model,
and in this way provide a simple way to support querying of their database using ADQL.
organisation
The SimDB is ready to be transferred to the DM WG.
We propose that Gerard Lemson keeps leading this effort (as main editor), also when it is moved
to that WG. The DM WG's chair (Mireille Louys) will be responsible all WG-chair
issues associated with moving a specification through the document process.
The people at the bottom will be part of a "tiger team" to push the standard to RFC.
We may want to expand this group with an expert from each of the WGs mentioned below.
We have been discussing the data model for some time now.
Various projects (Italy, USA, France and Germany) have implementations that are similar
to the envisioned SimDB. We believe that by autumn 2008 it can go to RFC.
Patriza Manzato and Rick Wagner will have reference implementations based on existing DBs,
so will various projects in France (Lyon: Jeremy Blaizot and Laurent Bourges;
Galmer database: Igor Chilingarian) and GAVO.
Other relevant working groups for this process are Registry, ADQL and Semantics, possibly DAL.
Registry because the simulation database is similar to a registry. We can
learn from implementations and the registry interface. Also, we (think we) may need an
extension to the IVO Identifier in the implementation of references in SimDB.
ADQL because we propose it to be the standard (main) query interface to a SimDB implementation.
Semantics because our model includes usage of semantic vocabularies, maybe full ontologies
DAL because we our proposal for using ADQL in the query phase requirs a version of
the TAP protocol for defining the interface.
We would like to include a person from each of these WGs in the tiger team.
Our wishes are: Ray Plante (Registry), ? (ADQL), Norman Gray (Semantics), (?) TAP.
Ray and Norm have contributed to early discussions about SNAP.
Of these other efforts it seems TAP offers the main risk for the SimDB standard to go to
RFC by the Autumn. What may help us is that we do not need all the details of TAP.
In particular the information_schema approach allowing users to
query for the data model is not required as it is part of SimDB specification.
We mainly need a prescription for sending ADQL queries to the SimDB, and what the
format of results should be.
Since we expect meta-data databases to be relatively small (compared to
say an SDSS or Millennium database), we expect fewer, if any problems with
performance and can stick to synchronous behaviour at first.
We may need some explicit registry-interface like features such as returning a
complete XML document according to the messaging format of the SimDB data model.
Other issues will come up during the next phase of the discussions.
Simulation Data Access Protocol (SimDAP)
The second spin-off of the SNAP project we propose we rename to Simulation Data Access Protocol (SimDAP).
It deals with accessing the data after discovery by some means,
likely trough an implementation of a Simulation Database.
It should handle special services such as cut-out, projection,
extraction (AMR-like cut-outs, produces regular grids), but also staging etc.
It should also deal with data formats. Claudio Gheller (Italy) is leading
this effort with close help of Rick Wagner (USA).
This project needs more fleshing out and is hopefully ready to be transmitted
to a WG, likely DAL by the Autumn interop.
Connections between SimDB and SimDAP
The two projects are connected as follows:
The meta-data formats to be included in SimDAP messages are derived from
the data model of the SimDB.
Vice versa, the SimDB will include a component describing
which SimDAP services are applicable/available for a given simulation.
2 Overview
2.1 SNAP ⇒ SimDB + SimDAP
This document presents a model for describing certain types of numerical computer simulations
and certain types of simulation post-processing products. The model was
originally
envisioned to
be used in the query part of the Simple Numerical Access Protocol (SNAP),
and in discovery of interesting SNAP services in the first place.
After investigating the application domain carefully,
and having tried to develop and implement a preliminary version of the former Simple Numerical Access Protocol, ADD A REFERENCE TO THE LAST SNAP DOCUMENT?
RV: In modelling (data, or physics or whatever) a given approach is never better per se (otherwize everybody should have done it in the past), in particular when the field under study is not unconnected to other related modelling efforts in close fields. This is the case of modelling in IVOA (not VO!) context. The community will be convinced it is better because their promoters are also able to demonstrate that other approaches - those the community decided to promote as a paradigm - failed to solve some major issues. We thus have to demonstrate somewhere in the document that our previous Simple(NAP) attempt failed because of some serious lacks. This needs a critical implementation analysis on a few test-beds (Laurent? that's what you did on GalMer and the first GalICS schema I guess).
we have decided to leave the concept of
designing a DAL-like SxAP protocol for simulations. Instead we have split up the effort into
two separate efforts that can be used each in their own right, though their is a clear link between them.
This document discusses the firsts of these, which we have named the Simulation Database, and
will have the acronym SimDB. The second will be developed further in a separate effort
and
is
called the Simulation Data Access Protocol (SimDAP, "Sim" stands for "Simulation", not "Simple"!).
Following SNAP, SimDB only explicitly considers simulations for systems that represent a space-time
sub-volume of the universe and (part of) its material contents. Examples of such simulations are
cosmological, pure dark matter N-body simulations of the large-scale structure of the universe;
adaptive mesh refinement (AMR) simulations following the evolution of a galaxy cluster using full hydrodynamics;
a simulation of the evolution of a globular cluster using a combination of tools, together simulating
the various types of physics @@ TODO reference to MODEST-like activities; or
simulations calculating the few seconds of a supernova explosion in full 3D.
In general these simulations will evolve this system forward
in time and are able to produce snapshots, representing the state of the system, a 3D volume of space,
at a number of discrete times (though there are alternatives: light cone simulations, individual particle orbits).
These direct, raw results of simulations we call Level-0 products, following
similar terminology for observations.
SimDB also covers Level-1 products, which consist of the results of certain types of post-processing
of simulations, namely those products that in some form create an alternative representation of
a spatial sub-volume of the universe. For example a density field calculated on a regular grid, derived
created from an N-body or an AMR simulation; a cluster catalogue derived using some group finder applied
to a cosmological simulation, or a synthetic galaxy catalogue derived from the cluster catalogue using
halo occupation distribution models (HODs) or semi-analytical models (SAMs).
We do not make any restrictions on the type @@ TODO DEFINE WHAT IS A 'TYPE'? (ASTRO-PHYSICAL OBJECT?) @@ of systems being simulated, or the size of the
simulation, or the way the system is represented in the simulation code and results. We also
make no restrictions on the type of "observables" produced by the simulations.
The SimDAP
specification will includes protocols for services that process Level-0 or Level-1 results and produce
other Level-1 results. The allowed services deal with selecting the results in a
sub-volume of the complete result, sampling a regular 3-dimensional grid, etc. SimDAP also allows for
services, that do not produce SimDB-like, Level-0 or 1 products. Examples are projections, 1D or 2D samplings.
But also custom services will be allowed, for example calculating statistical properties such as correlation
functions or power spectra in cosmological simulations. A more detailed description of SimDAP
is outside of the main scope of this note.
2.2 Simulation Database: structure, interface and applicable services
SimDB is a specification that defines the interface to a database containing meta data describing
simulations. To this end it contains two main parts, one is a model for the meta data, the other
a protocol for interacting with the database. The model is the core of the specification.
It describes the structure of individual data products in the database. We have chosen UML
as modelling language, as prescribed by the data modelling working group in the interoperability meeting
in Cambridge, UK, May 2003.
The UML model is a logical model (see [..] @@ TODO add reference @@) and
forms the basis for physical representations of the data products in the standard
language that the IVOA has chosen for such purposes, XML. We derive an XML schema defining valid
XML documents directly from the logical model. The SimDB interface will include functions for insetting
SimDB data products using such documents, and for retrieving individual, identified data products.
The logical model also forms the basis for a physical representation supporting formulation of queries.
For various reasons explained below we have chosen ADQL to be the query language and accordingly we derive
from the model a relational schema that defines the tables and columns that can be used in ADQL queries sent
to a SimDB implementation. The result of ADQL queries is supposed to be a VOTable, and this will in general
not represent a complete SimDB data product. However it can be used to browse the database, finally identifying
resources and possibly requesting these from the SimDB as XML documents.
We make very limited assumptions on how a data product discovered in a SimDB can actually be accessed.
We only assume there is a web-based service available, identified by a base URL and tagged with a service type.
The range of service types will be defined by SimDAP, but it will at least include "download" and "custom".
The data model contains an explicit element for indicating which services are available for a given data product,
and users may, if they wish, retrieve this information through ADQL queries and follow the links directly.
SimDB implementations can and likely will eventually provide SimDAP related functionality, but this is not part
of this specification.
2.3 Registration
It must be possible to find SimDB instances in an IVOA Resource Registry @@TODO add references&&.
This implies we need a corresponding resource type, and we have to design its structure.
We also assume that one may define resources in the sense of [...]
@@ TODO add reference to Resource data model document @@
from within the contents of a SimDB. We take this into account explicitly in the model.
The SimDB will have a "getIVOAResource" function, which will execute the appropriate transformation from
the internal representation of the SimDB data products to the Resource model's XML representation [...]
@@ TODO link to Resource XML schema document@@.
This will likely put more requirements on the Registry model itself, maybe requiring extensions to its schema.
Possibly a SimDB itself can be an extension registry. This we think can be postponed to a future version of the
specification.
2.4 Technology: UML, XMI, XSLT
We
2.5 Reference implementations
3 Usage scenarios
@@ TODO needs severe editing @@
We have assembled a list of explicit use cases and scenarios from which we derive
requirements for the current model and the former SNAP protocol.
3.1 "20 questions"
SimDB defines a common data model for simulations.
Following the good practice for database design initiated in [] @@TODO add references&&, we here provide a number of
scientific questions one might want to ask such a database. The data model and associated data
access protocol need to be sufficiently rich that they can support such questions.
- Scientific goal: investigate baryon wiggles in the evolved density field
Query: Return all cosmological, pure dark matter, N-body simulations with WMAP 3 initial
conditions and a box size of at least 1000 Mpc comoving, containing snapshots at about
10 redshifts between 3 and 0.
- Scientific goal: investigate whether observed structures in X-ray cluster that seem to
indicate turbulence, can truly be that.
Query: return all hydro-dynamical simulations of
galaxy clusters of mass at least 1014 Msun,
that have a model for viscosity included in the simulation.
Moreover, return only those simulations that have associated to them an online visualisation
service that can produce projected temperature and pressure maps.
- Scientific goal: interpret the possible histories of an observed galaxy merger to calculate
possible star formation episodes and compare these to the observed stellar populations.
Query: Return all simulations of galaxy mergers where the component galaxies have a particular
mass ratio and where there are enough snapshots to follow the evolution over a few Gyr.
- Scientific goal: compare the luminosity function of galaxies in the SDSS survey with those
in synthetic catalogues.
Query: Select all cosmological simulations that have produced as
secondary product synthetic galaxy catalogues on a light-cone and provide those via an SQL (ADQL?)
query interface.
- Scientific goal: compare a number of properties of
semi-analytical galaxies in large-scale dark matter simulations
predicted by two different set of parameters of a given
semi-analytical modelling tool.Query: Return the catalogues of
semi-analytical galaxies for a select number of semi-analytical runs made with different input parameters
in a given large-scale dark matter simulation.
@@ TODO MORE PRECISE QUERY @@
- Scientific goal: find N-body and hydrodynamical simulations with
comparable rotation curves than a set of spectroscopic
observations. Query: TODO QUERY
- ...
In the design of the model it is useful to think about the steps a user might go through
when querying a database system in various "drilling down" steps. For example the following
questions might be asked :
- What system/object is being simulated?
- What physical processes are included?
- How is the system being represented in the simulation
(particles (Langrangian), (adaptive) mesh (Eulerian)), both, other?
- Per process:
- How are the physical processes implemented ?
- Characterise the numerical approximations (.e.g. resolution, softening parameter)
- What observables are available for the system/object, possibly as function of time?
As it is a spatial system, at least simulation boxsize, center-of-mass position.
- What observables are available for the constituents, i.e. what is the schema of the atomic objects?
- Per snapshot, per atomic WHAT AN ATOMIC OBJECT TYPE ?? object type, per variable:
- Characterise the possible values
- Characterise the result
- Are post-processing results available?
- Are services/applications available working on the results?
- Which code ran the simulation?
- Which version of the code ?
- Who did make the simulations?
- What were values of physical parameters?
- How were initial conditions created, what parameters?
3.2 SimDB-standard implementation
We foresee a simple implementation scenario based directly on products developed
in the course of the SimDB effort. We believe that from the data model to be developed
in this effort we should be able to derive physical representations that
can be used directly in implementations. We envision that with only a little custom infrastructure code
it should be possible to
- fill a relational database with tables and views representing the SimDB data model from
DDL scripts generated from the UML
- create a web-based service that accept XML documents for inserting new simulation results
and translates these, using generated code with JAXB annotations, to in memory Java objects
- flush these objects to a relational database using the Java Persistence Architecture (JPA) implementation,
structured using the JPA annotations generated on the Java classes.
It should be not too hard to support other languages as well if they provide similar simple XML binding and
OR-mapping capabilities. Python+Django and C#+LINQ or NHibernate come to mind.
@@ TODO check with people knowing more about these technologies @@
- accept ADQL queries that are translated to the appropriate vendor specific SQL
(using modules defined by the ADQL effort?) and return a VOTable
- accept requests for identified SimDB resources (using an IVO or implementation specific identifier),
translate this into a JPA query to retrieve the object form the database, which is translated to
the appropriate XML using the JAXB layer and sent back to the user.
3.3 Legacy database
Although by no means as common as similar efforts in the observational domain,
databases have been developed containing the meta data of simulations.
How could a SimDB be implemented around such a database.
Our ideas are inspired by (what we understand from) the "global-as-view" approach to information
integration. We assume the implementers have their own way of filing up their database with meta-data
describing simulations from their own efforts. The idea is that they write database views to provide
a virtual implementation of the SimDB/RDB schema. ADQL queries sent to their service can now still be
understood and replied to. The users should also be able to write custom code to produce the appropriate
XML documents based on a request for an identified resource, possibly by querying these same views.
3.4 Meta data production pipe line
The SimDB data model is relatively comprehensive, which reflects itself in XML documents
of substantial size ad complexity for realistic cases.
For a registration scenario, i.e. one where a user is allowed to upload XML documents to a SimDB implementation,
one would prefer not to have to produce these documents by hand. By far the preferred manner in our opinion
would be for simulation and post-processing pipe-lines to produce compliant documents.
We have contacted authors of some of the most popular major simulation codes (Springel; Norman et al; more needed),
and they have agreed that this is feasible and are willing to participate in this effort.
3.5 Client tools
One reason to produce a standard which uses ADQL on top of a standard data model is that client tools
can be written to query different such holdings. For example we could envision a tool such as VisIVO [..]
to offer some user-friendly interface for querying SimDB implementations retrieved from an IVOA Registry.
The user need to see any ADQL, that is all generated by VisIVO, but can be shown results and services.
In particular if a cut-out service is available, VisIVO could provide an interface for the user to decide
on the sub-volume, retrieve and visualise it. The advantage of having a standard data model
clearly is that the same ADQL can be sent to all SimDB services.
@@ TODO contact VisIVO people to see whether this could be implemented @@.
4 Analysis model
@@TODO Gerard @@
An analysis model, also called domain model, is an abstract, high-level representation of the
universe of discourse (UoD), the part of the world that our application deals with.
It is a UML model, with emphasis on the concepts and their exact relationships in the UoD, though details
such as attributes need not be completely filled in.
Importantly, it should not be influenced by application scenarios apart form knowledge of their UoD.
Here we describe the UoD and our analysis model. The model is strongly influenced by patterns
discovered in earlier work on a
Domain model for Astronomy,
co-written by one of the authors of the present note. We describe some of its main patterns below as well.
@@ TODO or will we? @@
4.1 Universe of Discourse
4.2 Domain Model for Astronomy
4.3 SimDB analysis model
@@TODO create a version and add it to volute@@.
5 Logical Model: SimDB
Here we introduce the core of our proposal, the UML representation of our logical data model
for our Simulation Database. The exact representation of this model is an
XMI file,
which can be found in the snapdm section
of the Volute subversion database on Google code.
Other representations can be found in that same hierarchy, in particular check out the
HTML documentation which we generated from the XMI
representation with the XSLT pipeline described in Appendix B. This generated documentation file contains
the explicit description of all of the elements in the model and forms the reference documentation document for the model.
5.1 Overview
The logical data model is a fully detailed model of the application domain. It is to form the basis of physical
models, representing the model in various computational environments.
The logical model is represented as a set of UML diagrams, which we created using MagicDraw Community Edition 12.1 and stored as an
XMI file in the GoogleCode
SVN repository:
SNAP_Simulation_DM.xml @@TODO should change all occurrences of names with SNAP to using SimDB@@
JPG representations of the model can be found in this
directory. @@TODO find proper representation image of the complete model. Possibly color packages differently.@@
5.2 Normalisation
We have tried to find a balance in the level of normalisation of the data model.
5.3 Model contents
Here we discuss the actual contents of the model, though the detailed descritpion
5.3.1 Resource hierarchy
At the root of the SimDB data model is an abstract class called Resource, in the rest
of this document we will refere to this as SimDB/Resource.
It represents the different types of highest level meta-data objects to be stored in a SimDB.
Examples of this are represented as subclasses. First Experiment (SimDB/Experiment), which represents
different types of experiments that have been performed (run/executed/...) and have produced the results
that SimDB users may be interested in. Examples of SimDB/Experiment-s are first simulations,
but also the various post-processing operations transforming simulation results into other products
such as halo catalogues, density fields etc.
The second major type of SimDB/Resource is the SimDB/Protocol.
This concept represents a formally prescribed way of doing an experiment.
It is derived from the concept with the same name in the domain model, which itself was inspired
by the concept with the same name in Chapter 8.5 in [3].
In the SimDB/DM this concept has concrete representations in the computer programs that are being
used to run simulations and post-processing etc. As such it defines the possible input parameters,
possble algorithms, the kind of results that can be produced by the code. Every SimDB/Experiment must
indicate which SimDB/Protocol was used and for example provide values for the input parameters, indicate
which physics was used
The SimDB/Resource concept is clearly similar, but in general not equivalent to the Resource Registry's Resource concept.
In data modeling terms, it is not true that a SimDB/Resource is a Registry/Resource.
Often the reason is similar to the reasons that a single image is not a Registry/Resource, whereas a SIAP-compatible service is.
The granularity of a SimDB will be higher than a Registry and many simulations on their own will be too small.
The SimDB itself will have to be registered (see section ??? for a further discussion
@@ TODO add propoer section and href@@),
i.e. a SimDB service is a Registry/Resource. In discussion with Ray Plante (IVOA Interop May 2007, Beijing)
on this issue it was proposed that some part of the contents could also be registered in a Registry directly,
i.e. we should be able to identify Registry/Resource-s in SimDB. Considerations to decide on how to make this identification would be for example
that all data products resulting form a well defined (and published) scientific project could qualify.
To represent such a possibility for now we have introduced another subclass of SimDB/Resource: SimDB/Project.
This is not much more than an aggregation of experiments, with some additional atrributes describing the motivation etc.
The metadata of a SimDB/Project is not the same as that of a Registry/Resource, however we propose that we should be able
to define a transformation (possibly implemented again in XSLT) to transform a SimDB/Project and produce a Registry/XML representation.
Some more thoughts on this subject will be given in section ??? @@ TODO add proper section and href@@ mentioned above.
- Should we define explicit transformations for SimDB/Resource -> Registry/Resource ?
5.3.2 Object types
One of the main differences between the SimDB data model and other data models in the IVOA so far, is that we do not
know in advance what types of results we can expect.
imho, this difference is the most important and justifies a different approach; should be highlight at the beginning of the note
The Spectrum data model describes spectra, the characterisation data model
characterises observational results, the model implicit (for now) in SIA deals with 2D images etc.
This implies that many features describing these results can be explicitly modeled: Spectra have been taken of sources on the sky,
during a certain time persiod, covering a certain wavelength range. And fluxes were measured (in some form).
This makes it possible for space/time/wavelength/flux to make explicit appearances in the corresponding models.
In contrast, simulations come in a great variety of types, even if we constrain ourselves to the "3+1D" kind.
We can not make many assumptions on the type of objects making up the result, or on the "observables" of these objects.
It therefore becomes necessary to add components to the model that allow publishers to describe these explicitly.
We do so in the ObjectType hierarchy.
- Should we add units to the properties and not to the characterisations; similar for InputParameter and ParameterSetting
5.3.3 Target
The first question most people want to know about a simulations is: "what is being simulated?".
The answer should correspond to a real (astronomical) object, or collection of objects,
or possibly a physical process. For SimDB to answer such questions implies that publishers must be
able to describe these concepts in the model.
We have introduced the TargetObjectType and TargetProcess classes for this.... @@ TODO expand @@.
5.3.4 Characterisation
Much of the metadata in the model concerns itself with describing how the results that are supposedly the ultimate
goal of users, describing the kind of objects contained in the results and the scientific content. In an implementation of
the model as a database, one does not expect the actual data to be stored and therefore there is no need to have model elements
describing these. However there is some use to getting a summary of the actual data values, both obtained, and obtainable.
To this end we have added the characterisation elements, in reference to the Characterisation data model [5]
that, as we will try to explain, performs a similar function for observations.
@@ TODO expand @@
- We need to add characterisation to TargetObject, so users can ask for "simulations of 1e14 Msun galaxy clusters"
- Do we need other types of characterisation, such as accuracy etc?
5.3.5 Semantics
There are many instances in the data model where we need to describe elements of the
SimDB/Resource-s explicitly, because we do not have implicit information based on the context.
Examples are the various properties of object types, the target objects and processes etc.
Apart from a name and a description we then frequently add
an attribute which is supposed to "label" the element according to an assumed standard list of terms.
We model this using the
<<ontologyterm>>
stereotype. Attributes with this stereotype
are assumed to take their values form such a predefined "ontology". See
- We need to list the onotlogies that we create first attempts on some that do not yet exists.
- We need to have proper locations of machine readable vocabularies
- We need to get feedback on what kind of ontologies we want. Narrower/broader types, fully linked ontologies? etc
5.3.6 Units
The current (May 2008 @@ TODO update when necessary @@) version of the model
allows publishers to specify numerical quantities using a real value and a unit.
I.e. we do not prescribe units for particular quantities.
Allowing this flexibility in units assignment does pose a problem for a query interface that allows user to query on
characterisation values and other numerical quantities. ADQL does not include units for example, but a user
can not assume that every publisher will use the same unit for for example the typical size of a simulation box.
This is even worse of course for the characterisation values of properties that have to be defined
in the model and can have any kind of assumed unit.
We believe we should treat units as a special semantic vocabulary, possibly an ontology.
This implies we push its development off to elsewhere for now, and assume we can
at some point use a standard list of units in a similar way to the other ontology references.
Maybe this could include a link to the physical quantity (etc, see for example the
NIST reference on SI) to which the unit applies.
If this kind of link can be made, we could eventually attempt to impose a single unit to correspond to
all properties sharing a given quantity in the general sense.
This may lead to very small or very large values, depending on the simulation, but at least allows simpler
interfaces.
- We need input from the rest of the IVOA on how to deal with this issue
5.3.7 Services
The goal of the SimDB specification is to define a protocol for querying interesting simulations
and related SimDB/Resource-s.
Once these have been identified the user should be able to access these simulations.
We assume that web services are the means to do so, and allow publishers to indicate such
web services as are available for a given Experiment. We assume for now that we know little of the
web service beyond some generic types: download, cut-out, extraction, projection, custom.
The SimDAP specification is being developed to address those aspects in detail.
We assume that there will be a base-URL implementing some standard DAL (VOSI?) like services
and leave it up to SimDB-client implementations to interact with these services in standard manners.
Only custom services can be directly accessed, and for now many services will necessarily be custom.
- How do we get the complete list of service types? Predefined (as enumeration) in model?
6 Physical models
Here we describe how we create physical models out of the logical model.
A physical model is (see @@TODO reference to some standard reference on data modelling@@)
a representation of the logical model that is adapted to a particular software environment.
We present physical representations for the following contexts:
- XML: we present an XML schema defining valid XML documents
- Relational databases: we derive a relational database schema for storing instaces of the model.
- Java: we present Java classes representing the data model in a JVM. These classes are annotated with
Java Persistence API (JPA) and
Java Architecture for XML Binding (JAXB)
annotations to enable easy transformations to the XML and relational contexts.
- TAP: we present a representation of the model in a manner that hopefully has some similarity to the way
TAP will mandate meta-data about ADQL-queriable databases must be returned.
- UTYPE: we present for the simple, i.e. non-structured elements in the SimDB/DM serialisations taht should
resemble UTYPE-s. These can be used when representing (parts of) the model in VOTable.
- HTML: we present a representation of the model as a web browser (and human) readable HTML document.
This contains all details of the model in human readable form.
We have completely automated the derivation of these representations from the logical model using transformation
rules implemented in XSLT.
Our XSLT pipeline is described in more detail in Appendix B.
annotations, provides simple means to store contents of SimDB/XML documents in
a SimDB relational database and retrieve them from there again.
- Discuss adoption of this approach with DM WG
- Ultimately we believe that defining these mappings is the realm of the DM WG,
which might come up with a kind of meta-specification.
6.1 Identity and Referencing
The main elements in our data model are the object types, these embody the core concepts that we model.
In our approach we follow standard Object-Oriented design approaches
(see [10]) where object types are assumed to have an explicit identity.
Two objects (i.e instances of an object type) can have the same values for all fields, but if their identity is
not the same they are not the same object. Objects can be referenced by stating their identity (in whatever form this comes).
In contrast to this, value types are assumed to be identical if their value (or values, in the case of structured
value types) is the same.
In our UML model we have not defined an explicit identifier attribute on each object type to represent its identity,
its existence is assumed. There are some identifier-like attributes, but those refer to an identity the object has in abnother context,
generally the one of the publisher or creator of the object.
In most of the physical models we need to be able to represent this object identity explicitly however.
Related to this issue is that we need to be able to represent reference
relations between different objects.
Most contexts provide a natural mapping for references. For example relational databases have the concept of foreign keys,
XML documents allow references using ID/IDREF and other mechanisms for references to entities in the same document,
Java uses pointers (implicitly) to objects in the same virtual machine.
Problems arise when we need to leave the local contexts: references to resources not in the current database,
or in another XML document.
It is easy to imagine cases where this may occur. For example when registering a simulation run with the
open source Gadget [12] simulation code, one needs to have a reference to the corresponding Gadget SimDB/Simulator.
Unless one registers the experiment in the same SimDB where Gadget is registered, one needs to use a reference
across SimDB-s. One obvious way is to map all references to globally unique identifiers,
possibly using URIs or IVOA Identifiers [11].
The size of such URI-s makes this a rather expensive storage mechanism for use in a relational database,
certainly compared to simple integer (or bigint) columns.
This issue is not yet resolved satisfactory. The following possible approaches offer themselves and need discussions:
- Never allow references to objects not in the same SimDB.
This may require mirroring of resources not currently in the SimDB.
Registries have experience with similar such mechanisms, though likely for different reasons.
- Use complete URIs for all references, and allow references to objects not in the same SimDB.
This makes it impossible to have foreign keys on these references, as the referred to object may not exist.
It may be relatively expensive, though this may be reduced with an extra level of indirection.
If referenced SimDBs are themselves registered in each SimDB, they are themselves assigned the possibly smaller
local ID (an integer or bigint). A reference need then not require more than two IDs, possibly one if a standardised
mapping is used.
- Use IDs adjusted to the specific. for example use full URIs in XML documents, but resolve these to
smaller representations inside the database.
@@ TODO this needs rewriting, too much stream of consciousness @@
6.2 RDBM Schema
The public schema, i.e. the view the outside world has of a SimDB, is a relational schema.
This will be formally defined using VOTables containing the appropriate TABLE definitions.
Our Object-Relational mapping prescritpion contains the following elements:
- object types are mapped to tables, one table per object type
- Inheritance hierarchies: JOINED strategy as defined in JPA, i.e. each table only has columns for the attributes and references defined on the corresponding type.
Also an ID column that is a PK and also a FK to the ID of the base class' table. Possibly a container column (see below)
- Primary key column: ID NUMERIC(18)
- Foreign key to container: containerId
plus foreign key and index declaration
- References: <referenceName>Id
plus foreign key and index declaration.
- Using topological sort of object types based on (extends|container|reference) relations we generated
create table statements and ther indexes and foreign keys in blocks. drop table statements in opposite order.
- For each class we create a view named "v_<class name>"
returns all columns for that class; uses join to base class's view.
- generate a discriminator column on table for root in inheritance hierarchy, stores name of class (must be unique in inheritance hierarchy!)
- attributes mapped to single column if their type is simple (i.e. primitive, or enumeration)
- if attribute's type is dataType mapped to as many columns as the dataType has attributes,
with column names the name of the dataType's attributes, prefixed by <attribute-name>_
- For PK columns we use the
@@ TODO add links to actual generated schemas @@
6.3 XML Schema
The DM WG has mandated (IVOA interoperability meeting, Cambridge, UK, May 2003) that each data model should come with
an XML schema that represents valid XML serialisations of the data model.
We foresee that this representation can be used to communicate instances of SimDB/Resource-s as XML documents.
Such communication can be for registering new SimDB/Resources in a SimDB, or
used in message to communicate instances of the SimDB Resource type.
Here we shortly describe some of the rules for deriving an XML schema from our logical model.
- object and data types are mapped to comlexType. Object types inherit from a base class taht defines
features dealing with identity.
- primitiveType-s are mapped to appropriate simpleType-s
- enumerations are mapped to simpleType-s which are a restriction of xsd:string and have
an enumeration element for each literal.
- packages are mapped to namespaces and eahc package has its own file, with dependencies translated
to schema imports.
- A root element is generated for each concrete (i.e. non-abstract) root (i.e. not contained in other types)
object type.
- attributes are mapped to elements (not attributes!) of the appropriate type.
- collections are mapped to elements of the appropriate type, contained within the complexTYpe of the containing complexType
- references are mapped to a elements of a special purpose base complexType, Reference.
The precise definition of this type is postponed until the issues about identity and referencing is resolved.
For now it has multiple sub-elements reflecting the different possible ways to refer to other elements.
@@ TODO add links to actual generated schemas @@
6.4 UTYPE-s
It is generally the case that contents of databases may be represented in ways that do not
conform to one of the standard serialisations. Nothing prevents services to be developed on
top of SimDB that represent SimDB/Resource-s or even fragments of these in another form.
The standard example would be to have VOTables storing the results of a generic ADQL query of the SimDB/RDB representation.
VOTable first introduced the option to have a UTYPE attribute in FIELD definition tags store
a pointer to an element in a data model that the column represents.
The Spectrum data model was the first to add explicit
UTYPE-s for each of the attributes in its model and the Characterisation data model
has followed that example. As long as the precise usage and relation of the syntax of the underlying data model is
is not defined, we will follow these examples by assigning UTYPE-s explicitly to all elements in the model.
However, we will follow a fixed set of rules to makes this assignment and implement these in XSLT.
If a similar approach is at some time accepted within the IVOA, possibly in an alternative form, it will be straightforward
to adjust our definitions. The important point we want to make is that it is possible to simply define rules that then will
automatically produce the UTYPE-s for a given data model, i.e. the only discussion that is required is on the rules for doing so.
Our assumption is that the UTYPE should be able to uniquely represent any element in the data model, and in a manner
that is also easily interpreted. For now we assume that we need to point to those elements
that can be stored in a column in a VOTable, i.e. for now we are looking for "simple" elements.
We can use our relational mapping to identify all these features, they are
- attributes (paying attention to attributes with non simple data types)
- references (an identifier
identifying the referenced object) and
- collections (through a pointer to the containing, parent object).
VOTable also allows arrays to be stored in single columns, so a collection can be stored as an array of identifiers of
child objects. There are some other features that are not explicitly modelled, but are implied.
Examples are the identifier (ID) assigned to all objects and the name of the object type of an object.
Of course we could give each of the elements a uniquely generated identifier, but we assume that UTYPE-s should hold
semantic information, otherwise we could use the XMI-ids generated by the UML modelling tool.
To identify any of these elements uniquely within the context of the IVOA,
we then need the following components:
- name of element (possibly a path expression for structured attributes leading to a "leaf attribute")
- name of containing object type
- a path expression for the package(s) containing the object type
- unique identifier of the model, possibly its name if that is to be unique in the IVOA DM efforts
- some indication of the context, unless this can be implicit.
NB this assumes that we do not have a uniqueness rule on the names of object types within a model, something we do actually
assume in the mapping of SimDB/RDB above. In that case we could leave out the package path.
One could argue one could also give nice, unique names to each of the elements, but to find out what the actual element in
the model and in other representations one would still need to perform a look up. Such a uniqe name would likely include some of
the elements above anyhow. So we believe it would be a waste of efforts to do so and instead propose a simple convention
for deriving the UTYPE-s form the model based on this hiherarchy.
We have done so using these rules (in BNF-like notation)
- attribute
-
<model-name> ":" <package-name>[ "/" <package-name>]* "/" <objecttype-name> "." <attribute-name> [ "." <attribute-name>]*
- reference
-
<model-name> ":" <package-name>[ "/" <package-name>]* "/" <objecttype-name> "." <reference-name>
- collection (as array of p0inters to child objects)
-
<model-name> ":" <package-name>[ "/" <package-name>]* "/" <objecttype-name> "." <collection-name>
- container
-
<model-name> ":" <package-name>[ "/" <package-name>]* "/" <objecttype-name> "." "CONTAINER";
- ID
-
<model-name> ":" <package-name>[ "/" <package-name>]* "/" <objecttype-name> "." "ID";
- object type name
-
<model-name> ":" <package-name>[ "/" <package-name>]* "/" <objecttype-name> "." "DTYPE";
The HTML documentation generated from the logical model contains UTYPE-s for these features, generated according to these rules.
It will be obvious how to accommodate changes in the precise UTYPE specification, as long as similar rules are upheld.
@@ TODO add links to actual generated schemas @@
6.5 Java/JPA+JAXB (non normative)
7 Query Protocols
The previous chapter has defined a number of physical representations of the logical simulation data model.
Using these we can implement a database that can store instances of SimDB/Resources.
This could be done using an XML database, or using a relational database management system such as
Postgres, MySQL or any of the commercial versions. The data model is rather complex,
and more hierarchical than most other data models so far defined in the IVOA.
Querying such a data model requires a rich query language and we propose to use
ADQL working on the relational representation. ADQL produces tabular results, whose structure is completely
governed by the query itself. We also assume it possible, once appropriate information is available, to
retrieve complete SimDB/Resource-s as XML documents and propose a simple REST-like query interface for that.
Such an XML based interface will likely also be used to upload new resources to SimDB implementations taht support
that functionality.
7.1 ADQL + TAP
We expect no problems in formulating ADQL queries based on the relational representation of the data model
described in the previous chapter. We need to require an appropriate protocol for sending these queries to
a SimDB service though. In DAL work has started on the Table Access Protocol (TAP) and clearly some version
of that seems to be applicable to our situation. However there are some simplifying features.
Foremost is that we pre-define the relational schema, so a generic TAP "getMetadata" service seems not necessary.
There are likely going to be other standard DAL service features that we need to support (getCapabilities?),
but as meta data databases are expected to be relatively small we may again not require the full richness of
asynchronous querying, staging, VOSpace and what not.
Issues that need discussion:
- (How) does TAP deal with units?
- In TAP, does a table column containing values always have a single UCD and a single Unit?
- Is TAP suited for this kind of meta data databases?
7.2 REST
Under this heading we mean a protocol whereby data products can be retrieved through
HTTP GET requests. Possibly also they can be POST-ed, or PUT.
This needs to be discussed further, but maybe can be punted until a future release.
The GET will always only be able to get a complete SimDB resource, serialised to SimDB/XML,
similar to the IVOA Resource Registry interface @@ TODO is this actually a correct statement?@@.
8 Next Steps
8.1 Reference implementations
8.1.1 France
@@ TODO Laurent @@
8.1.2 Germany
@@ TODO Gerard @@
8.1.3 Italy
@@ TODO Patrizia @@
8.1.4 USA
@@ TODO Rick @@
s
8.2 Generating SimDB/XML documents from simulation pipe lines
Assigning meta-data to describe simulations etc is quite a lot of work if this is to be done aftre the fact.
It seems more fruitful to see if simulation codes could make the production of the appropriate
documents part of their pipe-line. It is our goal to contact the writers of some of the major
simulation packages and see whether they are willing to do so.
First contacts with Volker Springel (Gadget), the group in San Diego (Enzo) give us hope that this could
be achieved. The TIG should see it as its task to contact more authors of such codes and promote this idea further.
8.3 SimDAP services
Together with SimDB implementations we need to urge scientists to develop online services for accessing
their published simulations. Until the SimDAP specification is further developed these can be custom services,
but it is important that services are available asap. This outreach is a task for the TIG.
Appendix A: Data modelling specifics
Here we describe various aspects of UML modelling as we applied it to the current
problem area.
UML allows communities to create a domain specific modelling language through its Profiling capabilities
@@ TODO is this the proper term ?@@.
We have an initial implementation of a UML profile as created by MagicDraw available under
this link.
Here we list the main elements and give a a short motivation for their inclusion in the model/.
It is our opinion that the DM working group should be ultimately responsible for a profile such as this,
defining a domain specific language for all IVOA data modelling efforts.
As first step in our simulation pipeline we generate an XML document that represents the data model in a form
that is more easily interpreted, both by human readers and by XSLT scripts, than the XMI representation.
This document itself is structured according to an XML schema that
represents the UML profile rather directly and that we here shortly describe.
This schema is located in
http://volute.googlecode.com//svn/trunk/projects/theory/snapdm/input/intermediateModel.xsd.
We introduce our own XML format, defined by the XML schema in
intermediateModel.xsd,
for representing the logical model. For the time being we call this the intermediate representation.
The first step in the generation pipeline is a translation of the XMI to an XML document following this format.
This transformation is implemented in the
xmi2intermediate.xsl
XSLT script. The latest version of the intermediate representation for the SimDB data model can be found in
this location.
All other generation scripts work on this intermediate representation, not on the XMI document.
Variations in tool-generated XMI, or different versions of XMI can now be supported by an appropriately adjusted
XSLT script.
One reasons why this may be useful is that are different tools may produce different versions or different
dialects of XMI. Another reason for this representation is that XMI is a rather complex representation of a UML
model. Since we are using a rather restricted profile we do not need this generality, and
this allows us to represent the model using XML documents that are much easier to handle with XSLT.
We illustrate out UML profile using an example data model
derived form the SimDB/DM, shown in the following diagram:
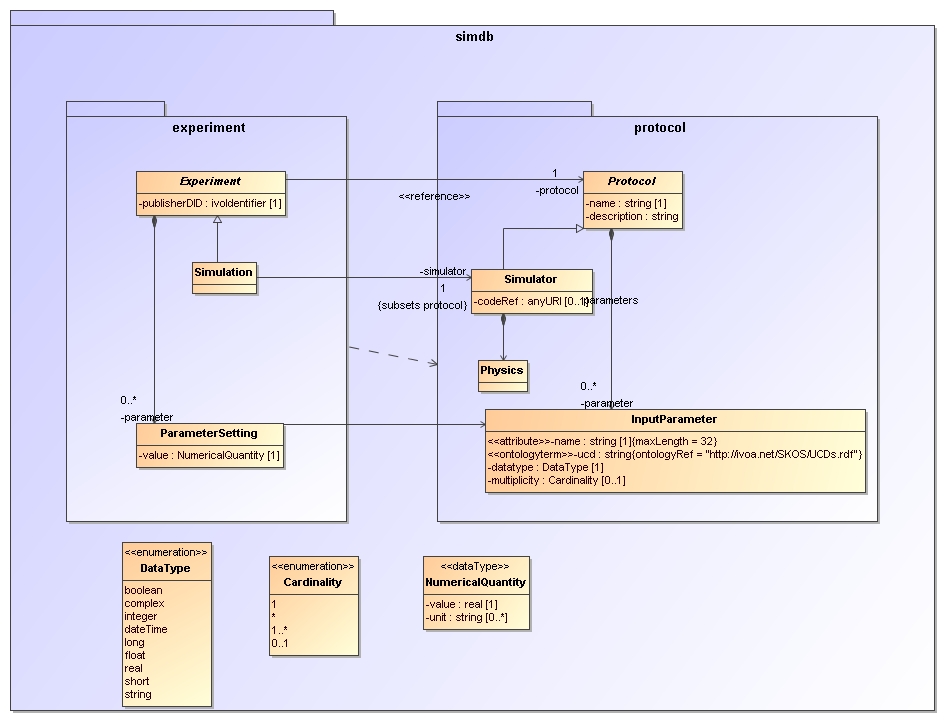
We now describe the individual elements.
some of these are standard, some of these are domain specific extensions following
standard UML profile stereotype extension elements and associated tag definition.
- Model (no visual counterpart)
-
-
- <<model>>
- TagDefinition: author
- TagDefinition: title
- Package

-
- package containment
- package dependency
- Class

-
- isAbstract
Indicated by italicised name of the object. Implies that no instances can be made of the class,
one needs sub classes for that.
- DataType

- Enumeration

- Property: attribute

-
- <<attribute>>
- TagDefinition: minLength
- TagDefinition: maxLength
- <<ontologyterm>>
There are many instances in the data model where we need to describe elements of the
SimDB/Resource-s explicitly, because we do not have implicit information based on the context.
Examples are the various properties of object types, the target objects and processes etc.
Apart from a name and a description we then frequently add
an attribute which is supposed to "label" the element according to an assumed standard list of terms.
We model this using the <<ontologyterm>>
stereotype. Attributes with this stereotype
are assumed to take their values form such a predefined "ontology".
- TagDefinition: ontologyURI
A URL locating a standard (RDF|SKOS|OWL|???) document containing
a list of terms from which the value for this attribute may be obtained.
It is our opinion that the Semantics working group should be responsible for the
definition of relevant ontologies (or semantic vocabularies, or thesauri, or ...)
required for a given application domain, though the contents should be decided in
cooperation with domain experts.
- Inheritance
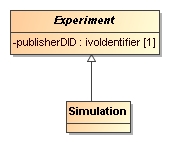
-
Indicates the typical is a relation between the sub-class and its base-class (the one pointed at).
In this profile we do not support multiple inheritance. @@ TODO explain? @@.
- Binary association end: collection

-
This relation indicates a composition relation between one, parent object and 0 or more child objects.
The life cycles of the child objects are governed by that of the parent.
- Binary association end: reference

-
This is a relation that indicates a kind of usage, or dependency of one object on another.
It is in general shared, i.e. many objects may reference a single other object. Accordingly the referenced
object is independent of the "referee". In our model the cardinality can not be > 1.
- Binary association end: subsets
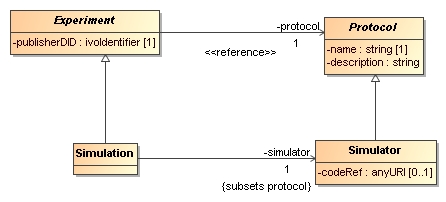
-
This indicates that a relation overrides a relation defined on a base class.
It does so by specifying that the class at the end point of the relation should be a subclass of the
class at the enpoint of the original, subsetted relation.
Appendix B: XSLT pipe line
@@ TODO Laurent @@
Glossary and Acronyms
- SimDB
- Acronym for Simulation Database, the standard that we propose to define in this Note.
Implementations of SimDB offer a query interface for discovering simulations (and related entities)
using ADQL, based on a prescribed (i.e.normative) relational data model and for describing simulations
via XML documents following prescribed XML (i.e. normative) schema.
- SimDAP
- Acronym for Simulation Data Access Protocol, a related standard to SimDB,
which will define services for accessing simulations discovered using SimDB.
- SimDB/DM
- The logical data model defining the structure of SimDB.
- SimDB/RDB
- The representation of the SimDB/DM as a relational data base schema.
This implies a parti
- SimDB/Views
- The representation of the SimDB/DM as a collection of database view definitions. Each View directly represents
a complete DM class as a relational table, this in contrast to the underlying SimDB/RDB representation in tables,
at least in the JOINED object-relational mapping strategy.
- SimDB/XML
- The XML representation of the SimDB/DM
- SimDB/Resource
- A top-level data product stored in a SimDB.
A SimDB/Resource can be described in a SimDB/XML document, but none of its constituents can.
- SimDB/TAP
- The TAP(-like) metadata representation of the SimDB/DM.
This is currently (May 2008 @@ TODO update once the TAP specification is out @@
a representation of the SimDB/Views as a VOTable document.
[1] ???, UML standard
http://
[2] ???, XMI standard
http://
[3] Martin Fowler, Analysis Patterns, 1997, Addison Wesley.
http://
[4] Lemson & Colberg, Theory in the virtual observatory
http://
[5] ???, Characterisation DM
http://
[6] @@ TODO @@references on global-as-view and information integration
http://
[7] @@ TODO @@reference to VisIVO
http://
[8] @@ TODO @@reference to Spectrum data model
http://
[9], Some links to pages on data model normalisation
http://www.datamodel.org/NormalizationRules.html
http://en.wikipedia.org/wiki/Database_normalization
[10], some data model references
http://www.agiledata.org/essays/dataModeling101.html
Meyer, B. Object Oriented Software Construction, 2nd edition, Prentice Hall, 1997
On object identity: http://en.wikipedia.org/wiki/Identity_(object-oriented_programming)
[11] @@ TODO @@reference to IVOA Identifiers ...
http://
[12] @@ TODO @@reference to Gadget ...
http://
