This note describes the data model to be used in the Simulation Database (SimDB) and Simulation Data Access Protocol (SimDAP).
The results presented in this note, which form the core of the proposed standard, are one aspect of a concerted effort
of the Theory Interest Group (TIG)
that originally went by the name Simple Numerical Access Protocol (SNAP), and is now split up in these two parts.
SimDB defines a publishing protocol for meta-data documents describing simulations and related "SimDB-resources", and
a query protocol for searching and browsing this database.
SimDAP defines protocols for accessing the simulation data products themselves. This part will be written up in a separate Note
(Gheller, Wagner et al, in preparation).
The current Note further separates out the description of the data model from the interface/protocol aspects of the full
SimDB specification. It was deemed useful to do so to simplify the standardisation track of SimDB/SimDAP.
We will describe the philosophy and design guidelines of the data model and its representations as
an XML schema and a relational database schema for use in the protocol.
The requirements will be written up in the SimDB document itself.
In this Note we are not discussing any motivations for our appproach using UML and the automated pipeline for
creating representations from the UML. This can be discussed elsewhere.
The main goal is to provide a discussion document for the SimDB/DM itself.
I.e. we assume that the decisions we have made concerning use of UML, assumption of a particular UML Profile, generation
rules from UML to XMl schema and relational schemas, use of identifiers, to be dealt with elsewhere.
We have proposed in the past that the DM WG is the appropriate place to have those discussions.
We feel that the data model is sufficiently far evolved that it could start following the formal IVOA standardisation track,
possibly in the context of the DM working group, but discussions are still not concluded what the appropriate path forward is.
This note could later be incorporated in a larger SimDB Note (from which it is now extracted) if that is deemed most
desirable.
This is a Note. The first release of this document was 2008 Sep 8, when it was extracted from the previous SimDB Note.
This is an IVOA Note expressing suggestions from and opinions of the authors.
It is intended to share best practices, possible approaches, or other perspectives on interoperability with the Virtual Observatory.
It should not be referenced or otherwise interpreted as a standard specification.
A list of
current IVOA Recommendations and other technical documents can be found at http://www.ivoa.net/Documents/.
We thank various persons for useful discussions in the course of this work. First the participants of the
Feb 2006 theory
workshop in Cambridge, UK, where this work was started. Second the participants of the
April 2007 SNAP workshop in
Garching, Germany, where the design started taking shape. Then we want to thank particularly the following persons
for useful discussions and feedback: Jeremy Blaizot, Klaus Dolag, Ray Plante, Volker Springel. We finally want to thank
participants to the theory sessions in the interoperability meetings in Victoria, Moscow, Beijing and Cambridge where parts
of this work was discussed.
1.1 Goal
The goal of the SimDB data model (SimDB/DM) is to describe "3+1D" simulations and their results
and related data products.
With this we mean simulations modelling a space-time sub-volume
of the universe of any size.
Typical examples are N-body simulations of galaxy mergers,
or the large-scale structure of the universe, or adaptive mesh refinement (AMR)
hydrodynamical simulations of galaxy clusters, star formation or supernovae.
The defining characteristic is that the results that are produced represent a spatial volume
of the universe, possibly evolving in time. The spatial volume in general will be 3D, though
simulations assuming some spatial symmetry may be 2D or 1D. Also, we expect at least one
such "snapshot", taken at a single time, but generally multiple snapshots are expected,
providing a discretised evolution in time. We will try to accomodate even more complex
sub-volumes of 3+1D space, such as light-cones representing a mock observed catalogue.
Finally there is no limit on the (spatial) scale of the simulations. We accomodate
the size of the universe down to stellar ot even sub-planetesimal scales.
Apart from "pure simulations" (to be defined later) we also include the results of
post-processing of such simulations, as long as their results are themselves again
representations of 3+1D space. So for example cluster finders on an N-body simulation,
producing a halo catalogue with positions and more complex properties are included,
as are regular spaced discrete density fields derived from an AMR result.
In the rest of this document we will in general use the term "simulation", but will
imply all allowed "experiments".
The model presented in this Note describes simulations at a rather detailed level, but stops short from
modeling the structure of the actual data products. It may therefore be called a meta-data
model.
Our goal is to define first a logical model in the sense of standard data
modelling approaches TODO add some references.
The logical model is based
on an analysis/domain model, which is not presented here, but is inspired by
the Domain Model for Astronomy.
From this we derive physical models, which are representations of the logical model
for use in the messaging and storage/query functions of the full SimDB specification.
In particular we present representations in the form of an XML Schema and
a relational database schema.
1.2 Usage by SimDB
SimDB is a set of web protocols to interact with an online database
containing metadata about simulations and related resources.
1.3 Usage by SimDAP
SimDAP is a set of web protocols to interact with web services
providing access to the results of SimDB simulations.
1.4 "20 questions"
SimDB defines a common data model for simulations.
Following the good practice for database design initiated in
Szalay et al (2000, [14])
we base our data model on a representative set of
scientific questions one might want to ask of a database containing descriptions of simulaiton data products.
The data model and associated data
access protocol need to be sufficiently rich that they can support such questions.
- Scientific goal: investigate baryon wiggles in the evolved density field
Query: Return all cosmological, pure dark matter, N-body simulations with WMAP 3 initial
conditions and a box size of at least 1000 Mpc comoving, containing snapshots at about
10 redshifts between 3 and 0.
- Scientific goal: investigate whether observed structures in X-ray cluster that seem to
indicate turbulence, can truly be that.
Query: return all hydro-dynamical simulations of
galaxy clusters of mass at least 1014 Msun,
that have a model for viscosity included in the simulation.
Moreover, return only those simulations that have associated to them an online visualisation
service that can produce projected temperature and pressure maps.
- Scientific goal: interpret the possible histories of an observed galaxy merger to calculate
possible star formation episodes and compare these to the observed stellar populations.
Query: Return all simulations of galaxy mergers where the component galaxies have a particular
mass ratio and where there are enough snapshots to follow the evolution over a few Gyr.
- Scientific goal: compare the luminosity function of galaxies in the SDSS survey with those
in synthetic catalogues.
Query: Select all cosmological simulations that have produced as
secondary product synthetic galaxy catalogues on a light-cone and provide those via an SQL (ADQL?)
query interface.
- Scientific goal: compare a number of properties of
semi-analytical galaxies in large-scale dark matter simulations
predicted by two different set of parameters of a given
semi-analytical modelling tool.
Query: Return the catalogues of
semi-analytical galaxies for a select number of semi-analytical runs made with different input parameters
in a given large-scale dark matter simulation.
@@ TODO MORE PRECISE QUERY @@
- Scientific goal: find N-body and hydrodynamical simulations with
comparable rotation curves than a set of spectroscopic
observations.
Query: TODO QUERY
- Scientific goal: find Protocols or Simulations that calculate the abundance of Neon IV of a cloud
Query: TODO QUERY
- ...
In the design of the model it is useful to think about the steps a user might go through
when querying a database system in various "drilling down" steps. For example the following
questions might be asked :
- What system/object is being simulated?
- What physical processes are included?
- How is the system being represented in the simulation
(particles (Langrangian), (adaptive) mesh (Eulerian)), both, other?
- Per process:
- How are the physical processes implemented ?
- Characterise the numerical approximations (.e.g. resolution, softening parameter)
- What observables are available for the system/object, possibly as function of time?
As it is a spatial system, at least simulation box
size, center-of-mass position.
- What observables are available for the constituents, i.e. what is the schema of the atomic objects?
- Per snapshot, per atomic WHAT IS AN ATOMIC OBJECT TYPE ?? object type, per variable:
- Characterise the possible values
- Characterise the result
- Are post-processing results available?
- Are services/applications available working on the results?
- Which code (version) wad used in the simulation?
- Who ran, owns, manages the simulations?
- What were values of physical parameters?
- How were initial conditions created, what parameters?
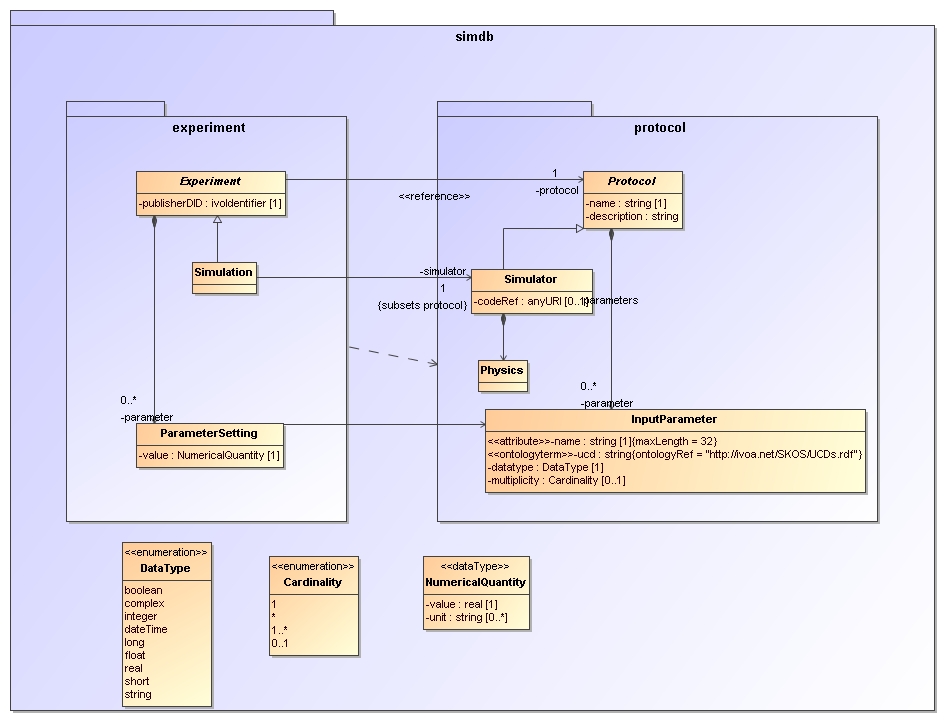
2 The data model (UML)
The data model is completely specified in UML 2 using MagicDraw community version 12.1 [TBD check].
The model is stored in an XMI document.
It contains all documentation of all the individual elements.
This model is the foundation from which all other secondary products such as XML schema and HTML documentation are derived.
In our collaboration we have used Google Code
for our resource (code, documents etc) management.
The particular resources for the SimDB project can be found under
http://volute.googlecode.com/svn/trunk/projects/theory/snapdm/.
In particular the UML document can be found here.
In appendix A we document the modelling elements that we have used, and the extensions that we
have made using the UML2 profiling functionality.
The following diagram is extracted from the UML modelling tool and shows most of the classes.

In the following sections we discuss various aspects of the model.
For the detailed documentation of all the elements in the model we refer to the
HTML document generated from the XMI
(NB need to get links to explicitly checked in versions of the generated documents).
2.1 Logic
The model is inspired by the Domain model for Astronomy.
To explain the logic behind both these models we build up a small version of it in steps.
We start with a File that we think others may be interested in retrieving because it contains astronomical data:

Instead of a file the data might also reside in a database, we will generically assume that data stored on some remote
system is represented in the model by a Storage element:

The reason why the data is potentially of interest is because it is the result of an (astronomical) experiment:

We do not assume that in reality the relation between the more conceptual Result and the concrete Storage element
is as simple as the simple reference, which seems to indicate that a result is always stored in a file for example.
Especially for the largely non-standardised world of simulations a single result can be distributed over many files.
In the actual SimDB model we therefore do not (currently) have an explicit Storage element.
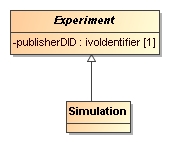
The abstract Experiment class is made more concrete by adding some examples of experiments that are important for the current model
dealing with simulations and simulation post-processing:

In our model, Experiment represents the actual running of an experiment, it does not itself describe all aspects of it.
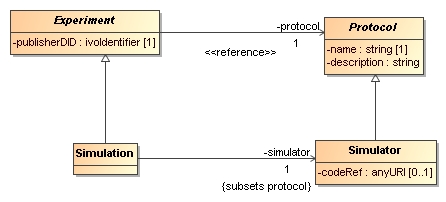
To describe the structure, the how of the experiment we introduce the abstract Protocol concept, "according to which"
an experiment is executed. Together with the abstract protocol we introduce more specific, more concrete subclasses, such
as Simulator, according to which a Simulation is run, and ClusterFinder, that describes the algorithms according which
a ClusterExtraction is performed:

One way in which a Protocol defines the structure of the experiment is by defining the input parameters that must be provided
for an actual run:

The experiment only needs to indicate the values for all of these parameters. In this way a single instance of the protocol
can be reused by many experiments performed according to it. The consequences of this normalised design, resolving possible
redundancies, will be discussed below. Other aspects of the protocol not shown in this simplistic model are how the results
are built up, or algorithms that are implemented in a simulation code.
One aspect of the experiment that is not determined by the protocol is why the experiment was performed.
In the model we introduce the Target concept for this, which represents real world objects or processes that are being investigated.
For example, with the same N-body simulator one may simulate a galaxy merger or the evolution of large scale structure:

As discussed above, the actual way in which results are stored in files or databases is hard, if not impossible to model.
Instead we assume that web services of various kind may be used to access the results of simulaitons and other
SimDB products.

Some of these will be standardised in the SimDAP specification, but custom services may also be introduced.
The model allows one to describe the experiments and their results, which should allow users to discover results
of interest, after which the webservices can be called for actually accessing these.
2.2 SimDB/Resource-s
The overall structure of the model is mainly based on different types of SimDB resources.
These are top elements in the model, ones that are not contained in a collection off another class.
They are similar to the resources in the Registry WG's Resource data model, but are not equivalent. In particular it is in
general (likely) not true that each SimDB/Resource (as we will refer to them) can also be registered in an IVOA Resource Registry, mainly because they
are too fine grained. Both Experiment and Protocol are Resources. To allow users to create a bundeling of pexperiments that belong together
we have added the Project. Projects might qualify to be registerd in a Resource Registry (Ray Plante, private communication), which is
one reason why it has been introduced as well. The metadata required for an IVOA Registry Resource is not as explicit and detailed
as that describing a SimDB/Resource, but should ideally be derived from it, possibly even in automated fashion.
This should be discussed further with the Registry WG..
SimDB's will allow registration of complete SimDB/Resource-s only.
In general our rule is that each concrete root-entity class (a class that is not in any way contained in another class)
will correspond to an XML document. The model currently has one root entity class that is not a resource, namely Party, representing
a person or organisation. In The Registry Resource model, this metadata finds a place in Curation.
Another issue we need to discuss with that WG.
The results of SimDB/Experiment-s are all assumed to be Snapshot-s. These represent a part of 3+1D space-time.
This is one of the features of the model that will have to be modified if we want to incorporate non-spatial simulations.
2.3 Normalisation
The current version of the SimDB/DM is rather more normalised than most of the other data models in
the IVOA (see the links on data model normalisation for some background on the subject).
We explain this concept based on a particular choice we made during the modelling process, then we discuss the consequences.
At an earlier stage, the model was less normalised in the design of the input parameters of an experiment.
Originally the model was as in the folowing diagram:

There was no separate protocol class, only an attribute protoclName on the Experiment
class indicated the protocol by which the experiment was run.
Also, the input parameters on the experiment were completely contained in a collection
of InputParameter-s. The InputParameter class contained all the details, including name of the parameter,
descritpion, UCD etc. It also contained the value of the parameter in the experiment.
Currently the model treats parameter definitions and settings as in the folowing diagram:

In this normalised design, the protocol is given a class of its own, and it contains the
input parameter collection.
The InputParameter classs does not contain the value anymore, only the definition of the parameter.
The values assigned to parameters in a given experiment are captured with the
ParameterSetting class, contained in a collection off Experiment. The motivation for this change of model was that
a SimDB will in general contain many simulations (experiments) run with the same simulator code (protocol).
In the old, denormalised model, each experiment would have to define the collection of input parameters
with all details: name, description, UCD etc. In the new design this only has to be defined once, on the appropriate
protocol. This clearly is less redundant, one design goal of normalisation.
It also in a sense provides an explicit identity to these parameters, which allows us to
ask explicit questions about all parameter settings for a given parameter. In the old model
this is only indirectly possible, using equality of the name of input parameters for all experiments
having the same protocolName. Now we can ask for all experiments with the same protocol reference,
and look for parameter settings with the same input parameter reference. This is clearly a more
"correct" model of reality.
There are therefore advantages to normalisation, but there are also also disadvantages.
We need to realise these and make choices that optimise the usability of the data model.
One of the main disadvantages is that references, which naturally have to be introduced when normalising a model,
are more difficult to deal with than most
of the other modelling elements, particularly in some physical representations (see below).
When defining a new experiment, one will have to find the input parameter that one needs to set, and instead of simply giving name/value,
one needs to represent the reference to the parameter. For this one may have to extract the
protocol as stored in the SimDB and find the appropriate identifiers of the input parameters
(see also below). In this sense an Experiment definition becomes less self-contained, it depends on
the definition of the Protocl, whihc is made separately (and at an earlier point in time!).
This puts strong requirements on SimDB implementations to maintain referential integrity,
something which is (would be) even harder to achieve if we were to allow cross-SimDB referencing.
For example, the UC San Diego version of SimDB would register the Enzo simulation code,
and the Italian SimDB would allow registration of Enzo experiments, referencing the remote protocol.
This for now we aim to disallow.
Similarly a query language needs to be able to handle with this level of indirection.
For example in a relational database one needs to write joins between ParameterSetting and InputParameter.
For expert SQL users this is not a problem, but is something to get used to.
For simpler query lannguages, those not allowing joins, like TAP/Param, asking meaningful queries becomes
very difficult. One way around this problem could be to add some view definitions to the model.
In relational databases, views are predefined, named SQL queries that can be treated as if they were
tables when querying the database.
It is quite straightforward to define some SQL queries that as it were denormalise the model
and put the input parameter definition back under the experiment together with the value.
This way one may protect users of the database from the high level of normalisation.
TODO discuss this further
2.4 Describing results: object types, object collections and characterisation
In contrast to a model for images or for spectra, we can not predict what type
of results a simulation or post-processing product will deliver.
Simplifying a bit, images contain pixels at a given sky position, measuring a flux.
Spectra contain pixels representing a given wavelength, again measuring a flux.
In our model we do not assume very much about the type of products produced
and hence these have to be explicitly described in the model.
In the domain model results are represented as in the following diagram,
which is a slight modification of the original:

Results consist of Object-s. Objects are described by an ObjectType.
The possible object types are predefined in the protocol and have Property-s.
Objects are instances of object types and consequently assign values to the properties.
The concept of an object type describing a result is that it should somehow correspond to the
"atomic building blocks' of a result. In our model a result should be seen as a colection of
these objects, therefore for an image it would correspond to a pixel, with properties location, flux, time.
For a source catalogue (result of a "source extraction experiment")
it corresponds to a source, with whatever properties the source extractor calculates.
In simulations it might be an N-body particle, with properties
(x, y, z, vx, vy, vz, mass) or an adaptive mesh refinement grid cell, with properties
(position, density, temperature).
In whatever form the actual result is stored, in principle one must be able to
identify these individual objects and their properties.
This is a model that could describe the actual data products. Objects, instances of object types
could be stored in a database for example. However, the current data model is not
that supposed to be that fine grained,
in contrast to the spectrum data model for example, which does contain the data elements.
The SimDB/DM is a model for metadata, and a detailed model for the datais beyond its scope.
Nevertheless it may be useful to have some indication of the actual results,
albeit not in all detail.
We have therefore looked for a way to summarise the detailed results.
This is very similar (in our opinion) to the approach taken in the
Characterisation data model and we use similar names.
In fact it follows the proposal for a
Characterisation domain model
that may be discussed further in the DM woorking group (private discussions with Mireille Louys and
Francois Bonnarel).
The following diagram shows our approach to characterising the contents of the results (which
ofcourse in the SimDB/DM are called Snapshot-s).

A snapshot has a collection of ObjectCollection-s, each of which represents a collection of objects of a single ObjectType.
This object collection concept did not exist in the domain model and could, maybe should be introduced there as well.
The object collection has a collection of Characterisation-s, each of which characterises a property of the object.
The interpretation is that from the collection of objects of a given object type, we can extract collections
of value(assignment)s, one for each property of the object type.
It is these collections that we want to summarise.
Precisely how this summary is made is defined by the type attribute on the Characterisation class.
It takes a value in an enumeration, examples of which are min, max, mean.
We expect this list to change, maybe become a semantic vocabulary, as it corresponds to various statistics
one could derive form the collections of properties.
We want to discuss the issue of characterisation in the SimDB/Dm further in the context
of the corresponding discussion in the DM WG.
2.5 The goal of an experiment: target objects and processes
Object types also play a role in the description of the goal of experiments.
One of the typical questions that scientists were interested in to find out about simulations is
"what was being simulated". The expected answers should be in terms of "real" astrophysical objects,
or possible processes. I.e. no technical description
Expand
2.6 Common vocabularies: semantics
Need input from Norman on this subject
In this data model, observables, object types, properties, parameters that play a role in a given simulation
have to be defined explicitly, for the world of simulations is too large to define all possilities in the model itself.
This in contrast for example to the spectrum data model [TBD add reference], where we know that a flux is determined
for a wavelength interval, or a model for images where a flux is determined for a spatial pixel.
In principle the publisher of a SimDB/Resource has all freedom to name and describe these entities.
For other users to understand the meaning of them, we have where appropriate, added an attribute corresponding to a semantic label.
This is similar to the situation in VOTable, where FIELD-s can be given a UCD (or UTYPE) that allows users to understand the
meaning of a column in the table.
In SimDB we need to generalise this concept as UCDs are not sufficient for our puspose.
For example target object types are not covered by the list of UCDs and the same for other elements in our model.
The Semantics WG is defining semantic vocabularies for use in the VO, for example of astronomical objects.
We try to anticipate
their results by introducing a special type of attribute in our UML profile that correspond to a concept in a given ontology.
Technically, we have defined a sterotype <<ontologyterm>> that can be assigned to an attribute in the UML model.
Attributes with this stereotype must define a value for the tag "ontologyURI".
This value must be a URI that points to a SKOS XML document defining a list of (top) concepts that are the valid values for the
attribute.
Concretely, in our model we have assigned this sterotype to the following attributes and assigned the indicated URIs.
Currently the URIs point to a location in the snapdm project in volute.
Eventuallly they should link to a location decided by the IVOA/Semantics group.
Issues:
- Design ok?
- Proper location for the SKOS vocabularies
- Proper assignment of vocabularies to attributes
- Potentially define new vocabularies
- What should the value be: the name of the SKOS concept, or its GUID, or ...?
- [VO-URP] For SimDB prototype need code for resolving the URI, retrieve the concepts, validate values etc.
- Should we settle on a specific version of the vocabularies? Or always take the latest, or ...?
- What are the issues we should take into account regarding the use of semantic vocabularies?
2.7 Quantities with units, open issue
At various locations in the SimDB data model numerical values can be defined, for example in parameter settings or
the characterisation of properties of representation object type collections. Often these numerical values will need to
have a unit. The IVOA has two ways of dealing with units.
Either units are fixed explicitly for properties/parameters in protocol or data model, sometimes depending on the small list of possible UCDs.
Alternatively units are epxlicitly stated, for example in VOTable.
At the moment we suppport the second mode, especially because, as is true for VOTable, we do not know what kind of
property is being used.
To this end we introduce a value type in the model, Quantity, which contains a value and a unit, and which is the data type
of various value attributes, for example in NumericalParameterSetting or Characterisation.
In the XML schema this is translated to a complexType with 2 elements, in the relational database schema to
two columns, one with the value, one with the unit.
It is in the use of the relational schema that we anticipate problems with this approach, especially in the query protocol to SimDB.
Consider the typical science question: return all N-body simulations with particle mass roughly
1010Msun.
In SimDB this would be need to be translated in an ADQL query which contains the unit column explicitly.
Allowing users freedom of registering SimDB resources using any units they desire can lead to resource
containing, for the same observable "N-body particle mass", values with a whole range of units.
To provide reasonable support to users requires the SimDB implementation to be able to do the automated transformation.
But in the
We propose in SimDB to use ADQL/TAP as the query interface. If units are stored explicitly users can
phrase queries using these,
An alternative approach is to mandate stating values for properties with a given UCD (or other semantic label)
always with the same units. This would solve the query problem but poses others.
For one it may be very (too?) unnatural for users to be forced to use meters for cosmological simulations,
or megaparsec for simulations in the solar system.
Related to this is the probably contentious discussion of what units to assign to what UCD.
One might choose SI or cgs units, but these are not always very useful or natural.
2.8 Services
When studying the SimDB/DM and comparing it to the explanation in section 2.1,
one will notice that there is no concept of storage for the results in the proposed model.
The reason is that whereas we can define the concept of a Result as collections of Objects quite
satisfactory, we have shied away of trying to model the precise way these results are actually
stored in files or a database. There are simply too many possible and actual ways in which
results can be stored in a file system.
In general, a result, or snapshot in our model, can not be modelled with a simple
reference to a file or table in which it is stored. Large results may be split up over many files,
stored as structs, or in arrays.
We have therefore decided not to open this can of worms (or reopen it, see the Quantity data model).
Instead we assume the existence of web services that allow users access to the results
of SimDB experiments. Some of these services may implement a standard protocol as defined
by SimDAP, or they may be custom services. The precise way to relate experiments to services
and what can be inferred about how to call them is the task of the SimDAP protocol.
expand?
2.9 Constraints
The UML profile (see Appendix A) allows
the definition of various types of constraints check that this is
described in the Appendix!.
For example we have constraints on the lengths of (string) attributes.
These are defined using tags on the <<attribute>> stereotype.
Other constraint on that stereotype are uniqueGlobally and uniqueInCollection.
The latter can for example be used to state that the names of properties on an
object type should be unique for that object type.
The former states that the attribute should be unique in the
Issues:
- do we want to generate uniqueness constraints on the database.
Not always feasible. Example, field defines name, but parameter wants
it to be unique in collection.
Maybe define uniqueness constraint on the Property view??
- check in Java code?
- how to enforce?
- Can/How do we use the UML model itself in any standard document.
Can we make statements like:
"A SimDB implementation MUST enforce all the rules from the UML model"?
Or do we have to stick to statements in terms of the physical representations?
But then we must be able to map the rules there.
Issue for DM WG
- some constraints can be checked in XML, some in code, some only in the database
(like global uniquenes)
DM WG may want to start thinking how to express constraints in a DM
3 Representations
Here we describe physical representations of the UML model for use in various
software environments. In particular we define representations for transmitting
instances of the model as XML documents using a set of XML schema definition
documents, and for storing instances in a relational database using a
set of DDL scripts.
We also propose a set of UTYPE-s for all the elements in the model for use for
example in VOTable representations of the model. The latter may be of use
when the results of ADQL queries aimed at the relational representation must
be serialised.
We end with some issues, a major one being the representation of identities of,
and references to objects.
3.1 TAP: RDBM Schema
We currently envision that the specification of the SimDB Protocol
will only contain a TAP-like interface
to the outside world, without defining the precise implementation of the TAP service.
We assume that a generic TAP interface will consist of table and possibly view
definitions that are accessible for querying using ADQL.
In principle we therefore only need to define the mapping of the UML model to this
TAP interface. As that specification is not finalised yet (as of 2008-10-05), we
make a guess at what its form will be. In fact, we make a few guesses.
The latest "official" versions of these are all presented in
the TAP area of the release section in "volute".
The mapping of the UML model to a relational database schema follows rather
standard Object-Relational Mapping (ORM) practice.
Classes are mapped to tables, attributes to columns, references to foreign keys.
Collections are mapped by a container foreign key from the child to the parent.
In general this is rather straightforward, in fact so much so that we propose
to define and fix this mapping explicitly for data models.
For the SimDB effort we have defined this mapping and implemented it using
a pipeline of XSLT scripts that transform the UML model stored as an XMI file, to
data definition language (DDL) scripts for a few popular databases.
Some choices have to be made here, for example we need to settle on a mapping from
(SimDB-)UML datatypes to SQL data types, or how to map inheritance hierarchies.
3.2 XML Schema
The mapping of a UML data model to XML schema is based on
suggestions in this presentation.
These were taken over by the Registry and VOTable groups in their various schema definitions.
First, we separate the declaration of xsd:complexType and xsd:simpleType
definitions and of root xsd:element-s in different
schema documents. The former "type-schemas" only define the structure of types, and
make no statement on their usage in specific documents.
The latter "element-schema" is our statement on how the types should be used in the SimDB context,
but other users might choose differently and only need to import the type schemas
to use these components.
To start with the type-schemas. We create a separate XML schema document
for each package. Each package document contains complexType and ismpleType definitions for the
object types and value types defined in the UML model.
Object types are mapped to xsd:complexType-s
and collections are mapped to xsd:element-s of the approppriate type and cardinality.
Inheritance is mapped to xsd:extension with a base attribute of the appropriate type.
Following some best practice suggestions attributes are mapped also to xsd:element-s and
not to xsd:attribute-s. This allows us to use the same pattern for attributes with
both simple and structured data types.
The former might be mapped to xsd:simpleType-s, but the latter require xsd:complexType-s,
which can not be assigned to xsd:attribute-s.
The problem comes with mapping references.
The containment relation represented by collections is a true parent-child relation,
with the life-cycle of the child object completely governed by that of the parent.
This implies that a child object can only exist within the context of the parent, and
therefore XML instances can be mapped to elements contained by the parent's element.
Reference relationships are in general different.
A reference to a certain object can in general be shared by many referrers.
The life cycle of the referred-to object is also independent of that of the referrer.
Hence a mapping of a reference as an element of the referred-to type is not natural.
It would also lead to great redundancy in the serialisation of the referring object.
For example, a SimDB/Experiment must reference a SimDB/Protocol.
The protocol is a complex object in its own right, and repeating this object in the referring
experiment is very expensive. Since furthermore many experiments can be performed according to the same protocol
there would be a great deal of redundancy if we were to map references to elements of
the referred-to type.
XML schema does allow a certain level of referencing, through its ID/IDREF data types (also through key/keyref mechanisms).
This can be used if a reference were to be mapped to an element of type xsd:IDREF, the value of which
should correspond to another element of type xsd:ID elsewhere in the same document.
This latter restriction makes this only a partial solution. In the example above it would force one to have
a representation of the protocol for each time an experiment is presented.
It can be a solution though if parameter groups are to be built from parameters defined in the same protocol
and our solution does allow for this.
This problem has been discussed now and then in the IVOA, in particular also in the context
of the STC data model I think this is correct, but should be checked. Maybe VOEvent?.
There a technical solut
3.3 UTYPE-s and HTML
3.4 Issue: Identity and Referencing
In the SimDB model all objects, i.e. instances of object types/classes, have an identity.
This is implicit in the UML model itself, but is made explicit in the serialisations to XML
schema and the relational model by assigning various types of identifiers to the objects,
represented as <xsd:element>-s in XML documents, or rows in tables.
Here we discuss various issues related to the assignment and use of these identifiers.
First, the motivation for assigning identifiers to all objects
This section currently contains notes from the discussions Laurent and Gerard had in Paris.
Needs to be written properly.
Issues:
- How does SimDAP deal with identities. discuss with Claudio and Rick
- Different identities possible: xmlId, ivoId, publisherDID, database id column
- generate ivoID? YES
- use attributes as id-s: name?
- need to resolve ID-s sent to us in an XML document
- is xmlId a publisherDID? NO
- should publisherDID be implicitly defined on all objects (i.e. on MetadataOjbect),
or only explicitly as on attribute on selected classes?YES (former, for now)
- SHould format of publisherDID be constrained?
YES, see SSA/SpectrumDM. Should be a valid IVO Identifier.
- role of uniqueness constraints for identifying
- is ivoId stored, or only computed on the fly?NO, (latter therefore)
- If we want to reference across SimDB instances, references may
need to store a complete ivoId.
The complexity associated to this is one reason (for now) to NOT reference
across instances !
TODO
-
look at registry model
-
look at IVO Identifier model
-
look at SSA/SpectrumDM
Use cases for identities:
uniquely identify SimDB/resources registered in a SimDB: ivoID (owned/assigned by SimDB)
for referencing, uniquely identify fragments of SimDB/resources in a SimDB
(e.g. parametersetting->inputparameter: ivoID, xmlId not enough as references go accross documents
Possible way to generate an ivoId form a dbID
ivo://<host-name>/<utype-to-class>/<dbid>#attribute/reference/collection
<utype-to-class> := <model-name>:<package-path>/<class-name>
A SimDB service must be registered. Therefore it will be given an ivoId.
This ivoId could be the prefix to the full id of the SimDB resources.
We want to be able to identify objects (= instances of classes)
- to find/retrieve resources by id
- to reference objects from another object
-
it may depend on the context (global, IVOA, SimDB, XML document, publisher's world,
data model collection (uniqueness constraint), ...)
how an object can be identified.
It may depend on the physical representation of the objects how to do this:
e.g.
- when createing a protocol XML doc we may want to be able to reference
- XML
Contexts of identity and reference:
On XML doc inserted into database:
identity (if it exists) may contain:
- xmlId
- publisherDID
reference contains:
- xmlId (if target object in same document)
- ivoId (if target object not in same document)
On XML doc, marshalled from the DB:
identity contains:
- ivoId (generated from database id and utype)
- xmlId (if referenced by object in same doc, generated on the fly)
- publisherDID (if provided by user)
reference contains:
- ivoId (of target object if not in same doc)
- xmlId (of target object if insame doc, generated on the fly!)
In database table:
- id (generated during insert)
- publisherDID (if provided by user)
All external contexts:
- ivoID
- possibly publisherDID, if sent to (SimDAP only?) web services that
user claims understand
TODO:
- add publisherDID to Identity (@Persistent).
- make ivoId and xmlId on Identity @Transient
- remove id from Identity?
- code up an ivoId generator, as well as ivoId interpreter/parser
- remove xmlId, ivoId from DDL, add publisherDID (replaces ivoId)
- when marshalling, generate xmlId-s, if necessary (Simulator_1234)
do first traversal to calculate xmlId-s for all objects to be marshalled
(in containment tree)
do 2nd traversal to set references:
- if target object has xmlId, use it
- if not, use ivoId
marshall
do 3rd traversal to set all xmlId-s back to null.
NB if JPA shares objects, has cache, this could cause problems.
So? Do not use shared cache. (alternative would be to use a solution taht
does not change the objects in memory, but this is more work, so decided against it.
In any case, only JPA@Transient fields are affected.
- generate a UTYPE element on the intermediate representation.
Q: When marshalling a SimDB/Resource, how to decide whether to use an xmlId or and ivoId for a reference?
A: Must depend on whether a referenced target object is in the same xml doc.
In future we may want to combine multiple resources in 1 doc.
In that case we can not guarantee that earlier defined xmlId-s are uniqe.
Also, at some point we hoprfully will allow definition of resources
interactively, not through xml. Then xmlId-s may not jhave been defined.
What this implies is that we better consider xmlId-s as transient objects, only of value within a document,
not for other purposes. If users want to add their own IDs, potentially.
Appendix A: Data modelling specifics
Here we describe various aspects of UML modelling as we applied it to the current
problem area.
UML allows communities to create a domain specific modelling language through its Profiling capabilities
@@ TODO is this the proper term ?@@.
We have an initial implementation of a UML profile as created by MagicDraw available under
this link.
Here we list the main elements and give a a short motivation for their inclusion in the model/.
It is our opinion that the DM working group should be ultimately responsible for a profile such as this,
defining a domain specific language for all IVOA data modelling efforts.
As first step in our simulation pipeline we generate an XML document that represents the data model in a form
that is more easily interpreted, both by human readers and by XSLT scripts, than the XMI representation.
This document itself is structured according to an XML schema that
represents the UML profile rather directly and that we here shortly describe.
This schema is located
here.
For the time being we call this the intermediate representation.
The first step in the generation pipeline is a translation of the XMI to an XML document following this format.
This transformation is implemented in the
xmi2intermediate.xsl
XSLT script. The latest version of the intermediate representation for the SimDB data model can be found in
this location.
All other generation scripts work on this intermediate representation, not on the XMI document.
Variations in tool-generated XMI, or different versions of XMI can now be supported by an appropriately adjusted
XSLT script.
One reasons why this may be useful is that are different tools may produce different versions or different
dialects of XMI. Another reason for this representation is that XMI is a rather complex representation of a UML
model. Since we are using a rather restricted profile we do not need this generality, and
this allows us to represent the model using XML documents that are much easier to handle with XSLT.
We illustrate out UML profile using an example data model
derived form the SimDB/DM, shown in the following diagram:
We now describe the individual elements.
some of these are standard, some of these are domain specific extensions following
standard UML profile stereotype extension elements and associated tag definition.
- Model (no visual counterpart)
-
- <<model>>
- TagDefinition: author
- TagDefinition: title
- Package

-
- package containment
- package dependency
- Class

-
- isAbstract
Indicated by italicised name of the object. Implies that no instances can be made of the class,
one needs sub classes for that.
- DataType

- Enumeration

- Property: attribute

-
- <<attribute>>
- TagDefinition: minLength
- TagDefinition: maxLength
- <<ontologyterm>>
There are many instances in the data model where we need to describe elements of the
SimDB/Resource-s explicitly, because we do not have implicit information based on the context.
Examples are the various properties of object types, the target objects and processes etc.
Apart from a name and a description we then frequently add
an attribute which is supposed to "label" the element according to an assumed standard list of terms.
We model this using the <<ontologyterm>>
stereotype. Attributes with this stereotype
are assumed to take their values form such a predefined "ontology".
- TagDefinition: ontologyURI
A URL locating a standard (RDF|SKOS|OWL|???) document containing
a list of terms from which the value for this attribute may be obtained.
It is our opinion that the Semantics working group should be responsible for the
definition of relevant ontologies (or semantic vocabularies, or thesauri, or ...)
required for a given application domain, though the contents should be decided in
cooperation with domain experts.
- Inheritance
-
Indicates the typical is a relation between the sub-class and its base-class (the one pointed at).
In this profile we do not support multiple inheritance. @@ TODO explain? @@.
- Binary association end: collection

-
This relation indicates a composition relation between one, parent object and 0 or more child objects.
The life cycles of the child objects are governed by that of the parent.
- Binary association end: reference

-
This is a relation that indicates a kind of usage, or dependency of one object on another.
It is in general shared, i.e. many objects may reference a single other object. Accordingly the referenced
object is independent of the "referee". In our model the cardinality can not be > 1.
- Binary association end: subsets
-
This indicates that a relation overrides a relation defined on a base class.
It does so by specifying that the class at the end point of the relation should be a subclass of the
class at the enpoint of the original, subsetted relation.
Glossary and Acronyms
- SimDB
- Acronym for Simulation Database, the standard that we propose to define in this Note.
Implementations of SimDB offer a query interface for discovering simulations (and related entities)
using ADQL, based on a prescribed (i.e.normative) relational data model and for describing simulations
via XML documents following prescribed XML (i.e. normative) schema.
- SimDAP
- Acronym for Simulation Data Access Protocol, a related standard to SimDB,
which will define services for accessing simulations discovered using SimDB.
- SimDB/DM
- The logical data model defining the structure of SimDB.
- SimDB/RDB
- The representation of the SimDB/DM as a relational data base schema.
This implies a parti
- SimDB/Views
- The representation of the SimDB/DM as a collection of database view definitions. Each View directly represents
a complete DM class as a relational table, this in contrast to the underlying SimDB/RDB representation in tables,
at least in the JOINED object-relational mapping strategy.
- SimDB/XML
- The XML representation of the SimDB/DM
- SimDB/Resource
- A top-level data product stored in a SimDB.
A SimDB/Resource can be described in a SimDB/XML document, but none of its constituents can.
- SimDB/TAP
- The TAP(-like) metadata representation of the SimDB/DM.
This is currently (May 2008 @@ TODO update once the TAP specification is out @@
a representation of the SimDB/Views as a VOTable document.
Related IVOA specifications, notes and other resources
A unified domain model for astronomy, for use in the Virtual Observatory
http://www.ivoa.net/internal/IVOA/IvoaDataModel/DomainModelv0.9.1.doc
Data Model for Astronomical DataSet Characterisation
http://www.ivoa.net/Documents/latest/CharacterisationDM.html
(see also the presentation on Characterisation in the Domain,
http://www.ivoa.net/internal/IVOA/InterOpMay2007DataModel/CharacterisationInTheDomain.ppt)
IVOA Identifiers
http://www.ivoa.net/Documents/latest/IDs.html
IVOA Spectral Data Model
http://www.ivoa.net/Documents/latest/SpectrumDM.html
Simulation Data Access Protocol (SimDAP)
TBD
Simulation Database (SimDB)
TBD
Theory in the virtual observatory
http://ivoa.net/pub/papers/TheoryInTheVO.pdf
Mapping UML to XML Schema
http://www.ivoa.net/internal/IVOA/VOResource010RevNotes/ModelBasedSchema.ppt
External links
Data modelling 101
http://www.agiledata.org/essays/dataModeling101.html
Data model normalisation
http://www.datamodel.org/NormalizationRules.html
http://en.wikipedia.org/wiki/Database_normalization
Identity (object-oriented programming)
http://en.wikipedia.org/wiki/Identity_(object-oriented_programming)
UML standard
http://www.uml.org/
XMI standard
http://www.omg.org/technology/documents/formal/xmi.htm
Fowler M., Analysis Patterns, 1997, Addison Wesley.
Meyer, B. Object Oriented Software Construction, 2nd edition, Prentice Hall, 1997
@@ TODO @@references on global-as-view and information integration
http://
