Custom CSS Classes :
Revision marks [revision] :
normal text
original text [citation]
=>
replacement text [proposal]
Authors :
Gerard's comments [gerard]
Laurent's comments [laurent]
In this note we propose that the IVOA develops a "meta-standard" for the design of IVOA data models and
derived products.
In this note we describe an initial version for such a meta-standard and an implementation of it.
We assume that one main usage of a data model is that instances of it ("objects") must be created and
represented by some means and stored for use by 3rd party users.
We assume therefore a generic DATABASE that stores these instances and that has services for
interaction with it. We assume two major modes of interaction: updates and query.
The first, we suggest, will include external users sending their DM instances represented as XML to the DATABSE.
The second will include allowing a user to send ADQL queries to the DATABASE for browing its contents.
The Simulation Database designed in the theory interest group was based on this approach
and its results will be used for examples now and then.
@@ TODO describe other usages, maybe concentrate on META-data models? @@
We propose that DM efforts should be built around a logical UML data model describing the application domain for a given
proposed standard specification in full detail. This model is designed using to a prescribed subset of the full UML modelling language,
which we represent with a UML profile.
TBD expand on profile.
For use in specific software contexts, physical models must be built based on this model.
Relevant examples are XML schemas, relational database schemas, Java classes, but also human readable documentation.
The second main feature of the proposed meta-standard is that these can be derived from the logical model
using a predefined and fixed set of mapping rules.
These rules must be decided on in the WG effort we propose here, but we provide a first attempts at
these and present these in this note.
We also provide an implementation of these rules as a set of XSLT [REF] scripts that transform the
logical model into the physical representations. We use here the fact that the logical model is represented
as XMI @@ TODO add REF@@, a standard XML format for representing UML models.
The main results of this note are
- A UML profile for creating logical data models (including intermediate XML
representation to buffer for XMI changes).
- Rules for mapping data models created according to the profile to
- XML schema
- Relational Database Schema (plus related TAP meta data representations)
- UTYPE-s
- Java classes annotated with JPA and JAXB attributes for translating between XML
and relational database representation
- A standard HTML documentation format
- JSP pages/TAG pages (LAUREN?) for browsing a DATABASE created with these components.
- A reference implementation of these rules using an XSLT pipe line.
We feel that the results presented in this note are sufficiently far evolved that the DM WG
might consider starting a project to work this out to a standard it proposes for DM efforts in the future.
This is a Note. The first release of this document was 2008 May 20.
The current version was edited 2008 May 20.
This is an IVOA Note expressing suggestions from and opinions of the authors.
It is intended to share best practices, possible approaches, or other perspectives on interoperability with the Virtual Observatory.
It should not be referenced or otherwise interpreted as a standard specification.
A list of
current IVOA Recommendations and other technical documents can be found at http://www.ivoa.net/Documents/.
We thank various persons for useful discussions in the course of this work. In particular Jeremy Blaizot,
for inviting GL and LB to Lyon to work on his Horizon project, where this project was conceived.
We thank the "tiger team" working on the SNAP and later SimDB project: Rick Wagner, Herve Wozniak, Patrizia Manzato and Mireille Louys.
And also the participants of the SNAP workshop in Garching, April 2007.
We propose a "meta-standard" for IVOA data modelling efforts that have as their goal defining meta-models
describing astronomical data products and related resources.
We propose that the DM WG defines a project to evaluate this proposal and if of interest
work out the details. So far this proposal has been followed by the Theory Interest Group in its
Simulation Database (SimDB) effort and has been shown to speed up development and produce standardised results
very efficiently.
We assume that data models are created with the goal of defining structured representations
according to which information about ones resources must be made available to the VO.
This includes storing such information in a database,
relational or otherwise, from which it can be queried; manipulating such information in code;
representing it in human and/or machine readable form for communication; and any combination of these.
These different usages must have in common that a given information item must be identifiable
irrespective of its representation. This implies that a common underlying model must be available,
from which the physical representations can be derived.
This realisation (which is by no means new!) forms the core of our proposal.
We propose that the core task of a data modelling effort should be to define this
so called logical model. The task of deriving the physical representation
should be no more than applying a standardised set of mapping rules.
TO make this work requires two components which we propose to the DM WG:
- A standardised representation of the core, logical model
-
A definition of the mapping rules, possibly encoded so that their application can be automated.
2 Data modelling
2.1 Analysis models
@@TODO Gerard @@
An analysis model, also called domain model, is an abstract, high-level representation of the
universe of discourse (UoD), the part of the world that our application deals with.
It is a UML model, with emphasis on the concepts and their exact relationships in the UoD, though details
such as attributes need not be completely filled in.
Importantly, it should not be influenced by application scenarios apart form knowledge of their UoD.
Here we describe the UoD and our analysis model. The model is strongly influenced by patterns
discovered in earlier work on a
Domain model for Astronomy,
co-written by one of the authors of the present note. We describe some of its main patterns below as well.
@@ TODO or will we? @@
2.1.1 Universe of Discourse
2.1.2 Domain Model for Astronomy
2.2 Logical Models
2.3 Physical Models
2.4 Representations as views
3. UML Profile
4 Mapping rules
A physical model is (see @@TODO reference to some standard reference on data modelling@@)
a representation of the logical model that is adapted to a particular software environment.
We propose that these are derived form a logical model described according to the profile using
mapping rules. The XMI representation of the logical model is particularly useful, as it
allows us to implement these rules i XSLT.
We present mapping rules for the following physical models:
- XML schema.
- Relational database schema.
- Java classes. In particular, Java classes annotated with
Java Persistence API (JPA) and
Java Architecture for XML Binding (JAXB)
annotations to enable easy transformations to the XML and relational contexts.
- TAP metadata. Rules define a representation of the model in a manner that hopefully has some similarity to the way
TAP will mandate meta-data about ADQL-queriable databases must be returned.
- UTYPEs: we present for the simple, i.e. non-structured elements in the SimDB/DM serialisations taht should
resemble UTYPE-s. These can be used when representing (parts of) the model in VOTable.
- HTML: we present a representation of the model as a web browser (and human) readable HTML document.
This contains all details of the model in human readable form.
We have completely automated the derivation of these representations from the logical model using transformation
rules implemented in XSLT.
Our XSLT pipeline is described in more detail in Appendix B.
4.1 Identity and Referencing
The main elements in our profile are the classes (=object types), these embody the core concepts that we model.
In our approach we follow standard Object-Oriented design approaches
(see [10]) where object types are assumed to have an explicit identity.
Two objects (i.e instances of an object type) can have the same values for all fields, but if their identity is
not the same they are not the same object. Objects can be referenced by stating their identity (in whatever form this comes).
In contrast to this, value types are assumed to be identical if their value (or values, in the case of structured
value types) is the same.
In our UML model we do not define an explicit identifier attribute on each object type to represent
its identity, its existence is assumed and its representation is up to the mapping to the physical model.
Related to this issue is that we need to be able to represent reference
relations between different objects.
Most contexts provide a natural mapping for references. For example relational databases have the concept of foreign keys,
XML documents allow references using ID/IDREF and other mechanisms for references to entities in the same document,
Java uses pointers (implicitly) to objects in the same virtual machine.
Problems arise when we need to leave the local contexts: references to resources not in the current database,
or in another XML document.
It is easy to imagine cases where this may occur. For example when registering a simulation run with the
open source Gadget [12] simulation code, one needs to have a reference to the corresponding Gadget SimDB/Simulator.
Unless one registers the experiment in the same SimDB where Gadget is registered, one needs to use a reference
across SimDB-s. One obvious way is to map all references to globally unique identifiers,
possibly using URIs or IVOA Identifiers [11].
The size of such URI-s makes this a rather expensive storage mechanism for use in a relational database,
certainly compared to simple integer (or bigint) columns.
This issue is not yet resolved satisfactory. The following possible approaches offer themselves and need discussions:
- Never allow references to objects not in the same SimDB.
This may require mirroring of resources not currently in the SimDB.
Registries have experience with similar such mechanisms, though likely for different reasons.
- Use complete URIs for all references, and allow references to objects not in the same SimDB.
This makes it impossible to have foreign keys on these references, as the referred to object may not exist.
It may be relatively expensive, though this may be reduced with an extra level of indirection.
If referenced SimDBs are themselves registered in each SimDB, they are themselves assigned the possibly smaller
local ID (an integer or bigint). A reference need then not require more than two IDs, possibly one if a standardised
mapping is used.
- Use IDs adjusted to the specific. for example use full URIs in XML documents, but resolve these to
smaller representations inside the database.
@@ TODO this needs rewriting, too much stream of consciousness @@
4.2 RDBM Schema
The public schema, i.e. the view the outside world has of a SimDB, is a relational schema.
This will be formally defined using VOTables containing the appropriate TABLE definitions.
Our Object-Relaitonal mappingprescritpion contains the following elements:
- object types are mapped to tables, one table per object type
- Inheritance hierarchies: JOINED strategy as defined in JPA, i.e. each table only has columns for the attributes and references defined on the corresponding type.
Also an ID column that is a PK and also a FK to the ID of the base class' table. Possibly a container column (see below)
- Primary key column: ID NUMERIC(18)
- Foreign key to container: containerId
plus foreign key and index declaration
- References: <referenceName>Id
plus foreign key and index declaration.
- Using topological sort of object types based on (extends|container|reference) relations we generated
create table statements and ther indexes and foreign keys in blocks. drop table statements in opposite order.
- For each class we create a view named "v_<class name>
returns all columns for that class; uses join to base class's view.
- generate a discriminator column on table for root in inheritance hierarchy, stores name of class (must be unique in inheritance hierarchy!)
- attributes mapped to single column if their type is simple (i.e. primitive, or enumeration)
- if attribute's type is dataType mapped to as many columns as the dataType has attributes,
with column names the name of the dataType's attributes, prefixed by <attribute-name>_
- For PK columns we use the
@@ TODO add links to actual generated schemas @@
4.3 XML Schema
The DM WG has mandated (IVOA interoperability meeting, Cambridge, UK, May 2003) that each data model should come with
an XML schema that represents valid XML serialisations of the data model.
We foresee that this representation can be used to communicate instances of SimDB/Resource-s as XML documents.
Such communication can be for registering new SimDB/Resources in a SimDB, or
used in message to communicate instances of the SimDB Resource type.
Here we shortly describe some of the rules for deriving an XML schema from our logical model.
- object and data types are mapped to comlexType. Object types inherit from a base class taht defines
features dealing with identity.
- primitiveType-s are mapped to appropriate simpleType-s
- enumerations are mapped to simpleType-s which are a restriction of xsd:string and have
an enumeration element for each literal.
- packages are mapped to namespaces and eahc package has its own file, with dependencies translated
to schema imports.
- A root element is generated for each concrete (i.e. non-abstract) root (i.e. not contained in other types)
object type.
- attributes are mapped to elements (not attributes!) of the appropriate type.
- collections are mapped to elements of the appropriate type, contained within the complexTYpe of the containing complexType
- references are mapped to a elements of a special purpose base complexType, Reference.
The precise definition of this type is postponed until the issues about identity and referencing is resolved.
For now it has multiple sub-elements reflecting the different possible ways to refer to other elements.
@@ TODO add links to actual generated schemas @@
4.4 UTYPE-s
It is generally the case that contents of databases may be represented in ways that do not
conform to one of the standard serialisations. Nothing prevents services to be developed on
top of SimDB that represent SimDB/Resource-s or even fragments of these in another form.
The standard example would be to have VOTables storing the results of a generic ADQL query of the SimDB/RDB representation.
VOTable first introduced the option to have a UTYPE attribute in FIELD definition tags store
a pointer to an element in a data model that the column represents.
The Spectrum data model was the first to add explicit
UTYPE-s for each of the attributes in its model and the Characterisaiton data model
has followed that example. As long as the precise usage and relation of the syntax of the underlying data model is
is not defined, we will follow these examples by assigning UTYPE-s explicitly to all elements in the model.
However, we will follow a fixed set of rules to makes this assignment and implement these in XSLT.
If a similar approach is at some time accepted within the IVOA, possibly in an alternative form, it will be straightforward
to adjust our definitions. The important point we want to make is that it is possible to simply define rules that then will
automatically produce the UTYPE-s for a given data model, i.e. the only discussion that is required is on the rules for doing so.
Our assumption is that the UTYPE should be able to uniquely represent any element in the data model, and in a manner
that is also easily interpreted. For now we assume that we need to point to those elements
that can be stored in a column in a VOTable, i.e. for now we are looking for "simple" elements.
We can use our relational mapping to identify all these features, they are
- attributes (paying attention to attributes with non simple data types)
- references (an identifier
identifying the referenced object) and
- collections (through a pointer to the containing, parent object).
VOTable also allows arrays to be stored in single columns, so a collection can be stored as an array of identifiers of
child objects. There are some other features that are not explicitly modelled, but are implied.
Examples are the identifier (ID) assigned to all objects and the name of the object type of an object.
Of course we could give each of the elements a uniquely generated identifier, but we assume that UTYPE-s should hold
semantic information, otherwise we could use the XMI-ids generated by the UML modelling tool.
To identify any of these elements uniquely within the context of the IVOA,
we then need the following components:
- name of element (possibly a path expression for structured attributes leading to a "leaf attribute")
- name of containing object type
- a path expression for the package(s) containing the object type
- unique identifier of the model, possibly its name if that is to be unique in the IVOA DM efforts
- some indication of the context, unless this can be implicit.
NB this assumes that we do not have a uniqueness rule on the names of object types within a model, something we do actually
assume in the mapping of SimDB/RDB above. In that case we could leave out the package path.
One could argue one could also give nice, unique names to each of the elements, but to find out what the actual element in
the model and in other representations one would still need to perform a look up. Such a uniqe name would likely include some of
the elements above anyhow. So we believe it would be a waste of efforts to do so and instead propose a simple convention
for deriving the UTYPE-s form the model based on this hiherarchy.
We have done so using these rules (in BNF-like notation)
- attribute
-
<model-name> ":" <package-name>[ "/" <package-name>]* "/" <objecttype-name> "." <attribute-name> [ "." <attribute-name>]*
- reference
-
<model-name> ":" <package-name>[ "/" <package-name>]* "/" <objecttype-name> "." <reference-name>
- collection (as array of p0inters to child objects)
-
<model-name> ":" <package-name>[ "/" <package-name>]* "/" <objecttype-name> "." <collection-name>
- container
-
<model-name> ":" <package-name>[ "/" <package-name>]* "/" <objecttype-name> "." "CONTAINER";
- ID
-
<model-name> ":" <package-name>[ "/" <package-name>]* "/" <objecttype-name> "." "ID";
- object type name
-
<model-name> ":" <package-name>[ "/" <package-name>]* "/" <objecttype-name> "." "DTYPE";
The HTML documentation generated from the logical model contains UTYPE-s for these features, generated according to these rules.
It will be obvious how to accommodate changes in the precise UTYPE specification, as long as similar rules are upheld.
@@ TODO add links to actual generated schemas @@
4.5 Java/JPA+JAXB (non normative)
5. Usage scenarios: METADATABASE
The previous chapter has defined a number of physical representations of the logical simulation data model.
Using these we can implement a database that can store instances of SimDB/Resources.
This could be done using an XML database, or using a relational database management system such as
Postgres, MySQL or any of the commercial versions. The data model is rather complex,
and more hierarchical than most other data models so far defined in the IVOA.
Querying such a data model requires a rich query language and we propose to use
ADQL working on the relational representation. ADQL produces tabular results, whose structure is completely
governed by the query itself. We also assume it possible, once appropriate information is available, to
retrieve complete SimDB/Resource-s as XML documents and propose a simple REST-like query interface for that.
Such an XML based interface will likely also be used to upload new resources to SimDB implementations taht support
that functionality.
5.1 ADQL + TAP
We expect no problems in formulating ADQL queries based on the relational representation of the data model
described in the previous chapter. We need to require an appropriate protocol for sending these queries to
a SimDB service though. In DAL work has started on the Table Access Protocol (TAP) and clearly some version
of that seems to be applicable to our situation. However there are some simplifying features.
Foremost is that we pre-define the relational schema, so a generic TAP "getMetadata" service seems not necessary.
There are likely going to be other standard DAL service features that we need to support (getCapabilities?),
but as meta data databases are expected to be relatively small we may again not require the full richness of
asynchronous querying, staging, VOSpace and what not.
Issues that need discussion:
- (How) does TAP deal with units?
- In TAP, does a table column containing values always have a single UCD and a single Unit?
- Is TAP suited for this kind of meta data databases?
5.2 REST
Under this heading we mean a protocol whereby data products can be retrieved through
HTTP GET requests. Possibly also they can be POST-ed, or PUT.
This needs to be discussed further, but maybe can be punted until a future release.
The GET will always only be able to get a complete SimDB resource, serialised to SimDB/XML,
similar to the IVOA Resource Registry interface @@ TODO is this actually a correct statement?@@.
Appendix A: Data modelling specifics
@@ TODO move to main text?@@
Here we describe various aspects of UML modelling as we applied it to the current
problem area.
UML allows communities to create a domain specific modelling language through its Profiling capabilities
@@ TODO is this the proper term ?@@.
We have an initial implementation of a UML profile as created by MagicDraw available under
this link.
Here we list the main elements and give a a short motivation for their inclusion in the model/.
It is our opinion that the DM working group should be ultimately responsible for a profile such as this,
defining a domain specific language for all IVOA data modelling efforts.
As first step in our simulation pipeline we generate an XML document that represents the data model in a form
that is more easily interpreted, both by human readers and by XSLT scripts, than the XMI representation.
This document itself is structured according to an XML schema that
represents the UML profile rather directly and that we here shortly describe.
This schema is located in
http://volute.googlecode.com//svn/trunk/projects/theory/snapdm/input/intermediateModel.xsd.
We introduce our own XML format, defined by the XML schema in
intermediateModel.xsd,
for representing the logical model. For the time being we call this the intermediate representation.
The first step in the generation pipeline is a translation of the XMI to an XML document following this format.
This transformation is implemented in the
xmi2intermediate.xsl
XSLT script. The latest version of the intermediate representation for the SimDB data model can be found in
this location.
All other generation scripts work on this intermediate representation, not on the XMI document.
Variations in tool-generated XMI, or different versions of XMI can now be supported by an appropriately adjusted
XSLT script.
One reasons why this may be useful is that are different tools may produce different versions or different
dialects of XMI. Another reason for this representation is that XMI is a rather complex representation of a UML
model. Since we are using a rather restricted profile we do not need this generality, and
this allows us to represent the model using XML documents that are much easier to handle with XSLT.
We illustrate out UML profile using an example data model
derived form the SimDB/DM, shown in the following diagram:
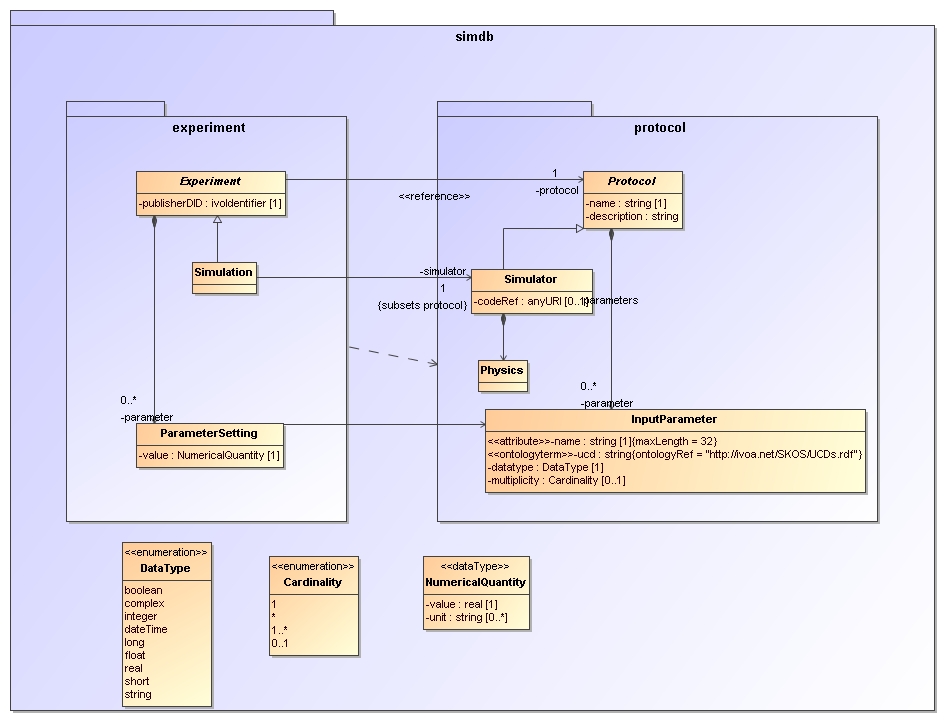
We now describe the individual elements.
some of these are standard, some of these are domain specific extensions following
standard UML profile stereotype extension elements and associated tag definition.
- Model (no visual counterpart)
-
-
- <<model>>
- TagDefinition: author
- TagDefinition: title
- Package

-
- package containment
- package dependency
- Class

-
- isAbstract
Indicated by italicised name of the object. Implies that no instances can be made of the class,
one needs sub classes for that.
- DataType

- Enumeration

- Property: attribute

-
- <<attribute>>
- TagDefinition: minLength
- TagDefinition: maxLength
- <<ontologyterm>>
There are many instances in the data model where we need to describe elements of the
SimDB/Resource-s explicitly, because we do not have implicit information based on the context.
Examples are the various properties of object types, the target objects and processes etc.
Apart from a name and a description we then frequently add
an attribute which is supposed to "label" the element according to an assumed standard list of terms.
We model this using the <<ontologyterm>>
stereotype. Attributes with this stereotype
are assumed to take their values form such a predefined "ontology".
- TagDefinition: ontologyURI
A URL locating a standard (RDF|SKOS|OWL|???) document containing
a list of terms from which the value for this attribute may be obtained.
It is our opinion that the Semantics working group should be responsible for the
definition of relevant ontologies (or semantic vocabularies, or thesauri, or ...)
required for a given application domain, though the contents should be decided in
cooperation with domain experts.
- Inheritance
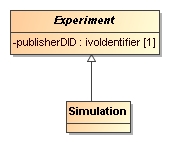
-
Indicates the typical is a relation between the sub-class and its base-class (the one pointed at).
In this profile we do not support multiple inheritance. @@ TODO explain? @@.
- Binary association end: collection

-
This relation indicates a composition relation between one, parent object and 0 or more child objects.
The life cycles of the child objects are governed by that of the parent.
- Binary association end: reference

-
This is a relation that indicates a kind of usage, or dependency of one object on another.
It is in general shared, i.e. many objects may reference a single other object. Accordingly the referenced
object is independent of the "referee". In our model the cardinality can not be > 1.
- Binary association end: subsets
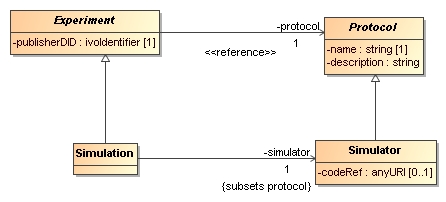
-
This indicates that a relation overrides a relation defined on a base class.
It does so by specifying that the class at the end point of the relation should be a subclass of the
class at the enpoint of the original, subsetted relation.
Appendix B: XSLT pipe line
@@ TODO Laurent @@
Glossary and Acronyms
- SimDB
- Acronym for Simulation Database, the standard that we propose to define in this Note.
Implementations of SimDB offer a query interface for discovering simulations (and related entities)
using ADQL, based on a prescribed (i.e.normative) relational data model and for describing simulations
via XML documents following prescribed XML (i.e. normative) schema.
- SimDAP
- Acronym for Simulation Data Access Protocol, a related standard to SimDB,
which will define services for accessing simulations discovered using SimDB.
- SimDB/DM
- The logical data model defining the structure of SimDB.
- SimDB/RDB
- The representation of the SimDB/DM as a relational data base schema.
This implies a parti
- SimDB/Views
- The representation of the SimDB/DM as a collection of database view definitions. Each View directly represents
a complete DM class as a relational table, this in contrast to the underlying SimDB/RDB representation in tables,
at least in the JOINED object-relational mapping strategy.
- SimDB/XML
- The XML representation of the SimDB/DM
- SimDB/Resource
- A top-level data product stored in a SimDB.
A SimDB/Resource can be described in a SimDB/XML document, but none of its constituents can.
- SimDB/TAP
- The TAP(-like) metadata representation of the SimDB/DM.
This is currently (May 2008 @@ TODO update once the TAP specification is out @@
a representation of the SimDB/Views as a VOTable document.
[1] ???, UML standard
http://
[2] ???, XMI standard
http://
[3] Martin Fowler, Analysis Patterns, 1997, Addison Wesley.
http://
[4] Lemson & Colberg, Theory in the virtual observatory
http://
[5] ???, Characterisation DM
http://
[6] @@ TODO @@references on global-as-view and information integration
http://
[7] @@ TODO @@reference to VisIVO
http://
[8] @@ TODO @@reference to Spectrum data model
http://
[9], Some links to pages on data model normalisation
http://www.datamodel.org/NormalizationRules.html
http://en.wikipedia.org/wiki/Database_normalization
[10], some data model references
http://www.agiledata.org/essays/dataModeling101.html
Meyer, B. Object Oriented Software Construction, 2nd edition, Prentice Hall, 1997
On object identity: http://en.wikipedia.org/wiki/Identity_(object-oriented_programming)
[11] @@ TODO @@reference to IVOA Identifiers ...
http://
[12] @@ TODO @@reference to Gadget ...
http://
