| Developer: Java
Taking JPA for a Test Drive
by Samudra Gupta
A case study in the use and deployment of the Java Persistence API (JPA)
Published November 2006
The
Summer 2006 release of the EJB 3.0 specification delivers a much
simplified but more powerful EJB framework that demonstrates a marked
preference for annotations over traditional EJB 2.x deployment
descriptors. Annotations, introduced in J2SE 5.0, are modifiers that
can be used in classes, fields, methods, parameters, local variables,
constructors, enumerations, and packages. Annotation use is highlighted
in a myriad of new EJB 3.0 features such as Plain Old Java Object-based
EJB classes, dependency injection of EJB manager classes, the
introduction of interceptors or methods that can intercept other
business method invocations, and a greatly enhanced Java Persistence
API (JPA).
To illustrate the concepts of JPA,
let's walk through a real-life example. Recently, my office had to
implement a tax registration system. Like most systems, it had its own
complexities and challenges. Because its particular challenge concerned
data access and object-relational mapping (ORM), we decided to
test-drive the new JPA while implementing the system.
We faced several challenges during the project:
- Relationships exist among entities use in the application.
- The application supports complex searches across relational data.
- The application must ensure data integrity.
- The application validates data before persisting it.
- Bulk operations are required.
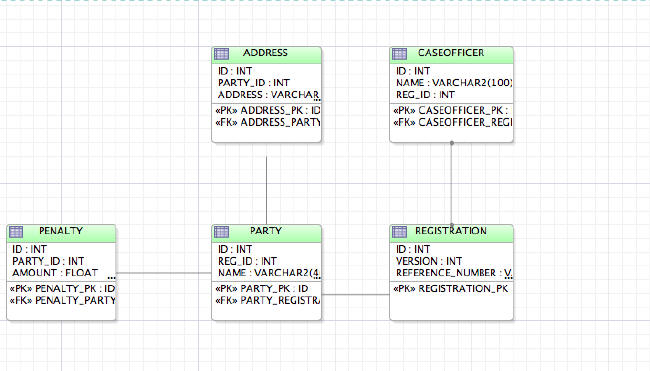
The Data Model
First
let's review a reduced version of our relation data model, which will
be sufficient to explain the nuances of JPA. From a business
perspective, a main applicant submits a tax registration application.
The applicant may have zero or more partners. Applicant and Partner
must specify two addresses viz. registered address and the trading
address. The main applicant also must declare and describe any
penalties he's received in past.
Defining Entities. We defined the following entities by mapping them to individual tables:
| Entity |
Tabled Mapped To |
| Registration |
REGISTRATION |
| Party |
PARTY |
| Address |
ADDRESS |
| Penalty |
PENALTY |
| CaseOfficer |
CASE_OFFICER |
Table 1. Entity-table mappings
Identifying the entities to map the database tables and columns
was easy. Here's a simplified example of the Registration entity. (I'll
introduce additional mappings and configurations for this entity later.)
@Entity
@Table(name="REGISTRATION")
public class Registration implements Serializable{
@Id
private int id;
@Column(name="REFERENCE_NUMBER")
private String referenceNumber;
..........
}
For us, the main benefit of using JPA entities
was that we felt as if we were coding routine Java classes: The
complicated lifecycle methods were gone. We could use annotations to
assign persistence features to the entities. We found that we didn't
need another extra layer of Data Transfer Objects (DTO) and that we
could re-use the entities to move between layers. Suddenly, data became
more mobile.
Supporting Polymorphism.
Looking at our data model, we noted that we used the PARTY table to
store both Applicant and Partner records. These records shared some
common attributes but also had individual attributes.
We
wanted to model this model in an inheritance hierarchy. With EJB 2.x,
we could use only one Party entity bean and then create Applicant or
Partner objects based on the party type by implementing the logic
within the code. JPA, on the other hand, let us specify the inheritance
hierarchy at the entity level.
We decided to model the inheritance hierarchy with an abstract Party entity and two concrete entities, Partner and Applicant:
@Entity
@Table(name="PARTY_DATA")
@Inheritance(strategy= InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name="PARTY_TYPE")
public abstract class Party implements Serializable{
@Id
protected int id;
@Column(name="REG_ID")
protected int regID;
protected String name;
.........
}
The two concrete classes, Partner and Applicant, will now inherit from the abstract Party class.
@Entity
@DiscriminatorValue("0")
public class Applicant extends Party{
@Column(name="TAX_REF_NO")
private String taxRefNumber;
@Column(name="INCORP_DATE")
private String incorporationDate;
........
}
If the party_type column has a value of 0, the
persistence provider will return an instance of Applicant entity; if
the value is 1, it will return an instance of Partner entity.
Building relationships.
The PARTY table in our application data model contains a foreign-key
column (reg_id) to the REGISTRATION table. In this structure, the Party
entity becomes the owning side of the entity or the source of the
relationship because it's where we specify the join column.
Registration becomes the target of the relationship.
With
every ManyToOne relationship, it's more likely that the relationship is
bi-directional; that is, there will also be a OneToMany relationship
between two entities. The table below shows our relationship
definitions:
>
| Relationship |
Owning Side |
Multiplicity/Mapping |
| Registration->CaseOfficer |
CaseOfficer |
OneToOne |
| Registration->Party |
Party |
ManyToOne |
| Party->Address |
Address |
ManyToOne |
| Party->Penalty |
Penalty |
ManyToOne |
| Reverse Side of Relationship |
| Registration->CaseOfficer |
|
OneToOne |
| Registration->Party |
|
OneToMany |
| Party->Address |
|
OneToMany |
| Party->Penalty |
|
OneToMany |
Table 2. The relationships
public class Registration implements Serializable{
....
@OneToMany(mappedBy = "registration")
private Collection<Party> parties;
....
}
public abstract class Party implements Serializable{
....
@ManyToOne
@JoinColumn(name="REG_ID")
private Registration registration;
....
Note: The mappedBy element indicates that the join column is specified at the other end of the relationship.
Next,
we had to consider the behavior of the relationships as defined by the
JPA specification and implemented by persistence providers. How did we
want to fetch the related data—EAGER or LAZY? We looked at the default
FETCH types for relationships as defined by JPA, and then added an
extra column to Table 2 to include our findings:
| Relationship |
Owning Side |
Multiplicity/Mapping |
Default FETCH Type |
| Registration->CaseOfficer |
CaseOfficer |
OneToOne |
EAGER |
| Party->Registration |
Party |
ManyToOne |
EAGER |
| Address->Party |
Address |
ManyToOne |
EAGER |
| Penalty->Party |
Penalty |
ManyToOne |
EAGER |
|
|
|
|
| Reverse Side of Relationship |
| Registration->Party |
|
OneToMany |
LAZY |
| Party->Address |
|
OneToMany |
LAZY |
| Party->Penalty |
|
OneToMany |
LAZY |
Table 3. Setting default FETCH types
Looking
at the business requirement, it appeared that when we obtained
Registration details, we'd always have to display the details of the
Party associated with that registration. With the FETCH type set to
LAZY, we'd have to make repetitive calls to the database to obtain
data. This implied that we'd get better performance if we changed the
Registration->Party relationship to the FETCH type EAGER. With that
setting, the persistence provider would return the related data as part
of a single SQL.
Similarly, when we displayed the
Party details on screen we needed to display its associated
Address(es). Thus, it also made sense to change the Party-Address
relationship to use the EAGER fetch type.
On the
other hand, we could set the Party->Penalty relationship FETCH type
to LAZY since we didn't need to display the details of penalties unless
a user requested them. If we used the EAGER fetch type, for m number of
parties having n number of penalties each, we'd end up loading m*n
number of Penalty entities, which would result in an unnecessarily
large object graph and degrade performance.
public class Registration implements Serializable{
@OneToMany(mappedBy = "registration", fetch = FetchType.EAGER)
private Collection<Party> parties;
.....
}
public abstract class Party implements Serializable{
@OneToMany (mappedBy = "party", fetch = FetchType.EAGER)
private Collection<Address> addresses;
@OneToMany (mappedBy = "party", fetch=FetchType.LAZY)
private Collection<Penalty> penalties;
.....
}
Accessing lazy relationships.
When considering using a lazy loading approach, consider the scope of
the persistence context. You can choose between an EXTENDED persistence
context or a TRANSACTION scoped persistence context. An EXTENDED
persistence context stays alive between transactions and acts much like
a stateful session bean.
Because our application isn't
conversational, the persistence context didn't have to be durable
between transactions; thus, we decided to use the TRANSACTION scoped
persistence context. However, this posed a problem with lazy loading.
Once an entity is fetched and the transaction has ended, the entity
becomes detached. In our application, trying to load any lazily loaded
relationship data will result in an undefined behavior.
In
most cases, when caseworkers retrieve a registration data back, we
don't need to display penalty records. But for managers, we need to
additionally display the penalty records. Considering that most of the
times, we need NOT display the penalty records, it would make no sense
to change the relationship FETCH type to EAGER. Instead, we can trigger
the lazy loading of the relationship data by detecting when a manager
is using the system. This will make the relationship data available
even when the entity is detached and can be accessed later. The example
below explains the concept:
Registration registration = em.find(Registration.class, regID);
Collection<Party> parties = registration.getParties();
for (Iterator<Party> iterator = parties.iterator(); iterator.hasNext();) {
Party party = iterator.next();
party.getPenalties().size();
}
return registration;
In
the above example, we just invoke the size() methods of the penalties
collection of the Party entity. This does the trick and triggers the
lazy loading and all the collections will be populated and available
even when the Registration entity is detached. (Alternatively, you can
use a special feature of JP-QL called FETCH JOIN, which we shall
examine later in the article.)
Relationships and Persistence
Next, we had to
consider how the relationships behaved in the context of persisting
data. In essence, if we made any changes to the relationship data, we
wanted to do so at the object level and have the changes persisted by
the persistence provider. In JPA, we can use CASCADE types to control
the persistence behavior.
There are four CASCADE types defined within JPA:
- PERSIST: When the owning entity is persisted, all its related data is also persisted.
- MERGE: When a detached entity is merged back to an active persistence context, all its related data is also merged.
- REMOVE: When an entity is removed, all its related data is also removed.
- ALL: All the above applies.
Creating an entity.
We decided that in all cases, when we created a new parent entity, we
wanted all its related child entities to also be persisted
automatically. This made coding easier: We just had to set the
relationship data correctly and we didn't need to invoke the persist()
operation on each entity separately. This means coding is easier this
way, as we just have had to set the relationship data correctly and we
don't didn't need to invoke the persist() operation on each entity
separately.
So, cascade type PERSIST was the most attractive option for us. We refactored all our relationship definitions to use it.
Updating an entity
It's common to obtain data within a transaction and then make changes
to the entities outside the transaction and persist the changes. For
example, in our application, users could retrieve an existing
registration and change the address of the main applicant. When we
obtain an existing Registration entity and thus, all of its related
data within a particular transaction, the transaction ends there and
the data is sent to the presentation layer. At this point, the
Registration and all other related entity instances become detached
from the persistence context.
In JPA, to persist
the changes on a detached entity, we use the EntityManager's merge()
operation. Also, in order to propagate the changes to the relationship
data, all the relationship definitions must include CASCADE type MERGE
along with any other CASCADE type defined in the relationship mapping's
configuration.
With this background, we made sure that we specified the correct CASCADE types for all relationship definitions.
Removing an entity.
Next, we had to determine what would happen when we deleted or removed
certain entities. For example, if we deleted a Registration, we could
safely delete all the Party(s) associated with that Registration. But
the reverse is not true. The trick here is to avoid any unwanted
removal of entities by cascading the remove() operation on the
relationship. As you'll see in the next section, such operations may
not succeed because of referential integrity constraints.
We concluded that in a clear parent-child
relationship such as Party and Address or Party and Penalty, which
follow OnetoMany relationships, it's safe to specify the CASCADE type
REMOVE only on the parent (ONE) side of the relationship. We then
refactored the relationship definitions accordingly.
public abstract class Party implements Serializable{
@OneToMany (mappedBy = "party", fetch = FetchType.EAGER, cascade =
{CascadeType.PERSIST, CascadeType.MERGE, CascadeType.REMOVE})
private Collection<Address> addresses;
@OneToMany (mappedBy = "party", fetch=FetchType.LAZY, cascade =
{CascadeType.PERSIST, CascadeType.MERGE, CascadeType.REMOVE})
private Collection<Penalty> penalties;
.....
}
Managing Relationships
According
to JPA, managing relationships is the sole responsibility of the
programmer. Persistence providers don't assume anything about the state
of relationship data, so they don't attempt to manage the relationship.
Given this fact, we re-examined our strategy to
manage relationships and pinpoint potential problem areas. We
discovered the following:
- If we try to set a
relationship between a parent and the child, and the parent no longer
exists in the database (perhaps it was removed by another user), this
will lead to data integrity issues.
- If we try to delete a parent record without first removing its child record, a referential integrity will be violated.
Thus, we mandated the following coding guidelines:
- If
we obtain an entity and its related entities in a transaction, change
the relationship outside the transaction, and then try to persist the
changes within a new transaction, it's best to re-fetch the parent
entity.
- If we try to delete a parent record without deleting the child
records, we must set the foreign-key field for all children to NULL
before removing the parent.
Consider
the OneToOne relationship between CaseWorker and Registration. When we
delete a particular registration, we don't delete the caseworker; thus,
we need to set the reg_id foreign key to null before we delete any
registration.
@Stateless
public class RegManager {
.....
public void deleteReg(int regId){
Registration reg = em.find(Registration.class, regId);
CaseOfficer officer =reg.getCaseOfficer();
officer.setRegistration(null);
em.remove(reg);
}
}
Data Integrity
When a user
is viewing a registration record, another user might be making changes
to the same application. If the first user then makes additional
changes to the application, he risks unknowingly overwriting it with
old data.
To address this issue, we decided to use "optimistic locking." In
JPA, entities can define a versioning column, which we can use to
implement the optimistic locking.
public class Registration implements Serializable{
@Version
private int version;
.....
}
The persistence provider will match the in-memory
value of the version column with that of the database. If the values
are different, the persistence provider will report an exception.
Validation
When we say that the main applicant must have at least one address
and the address must at least contain the first line and the post code,
we're applying a business rule across the Party and Address entities.
However, if we say that each address line must always be less than 100
characters, this validation is intrinsic to the Address entity.
In our application, we decided to implement the cross
object/business rules type validations into the Session Bean layer
because that's where most of the workflow and process-oriented logic is
coded. However, we placed the intrinsic validations within the
entities. Using JPA, we could associate any method to a lifecycle event
for an entity.
The following example validates that an Address line can contain no
more than 100 characters and invokes this method before the Address
entity is persisted (with a @PrePersist annotation). Upon failure, this
method will throw a business exception (which extends from
RuntimeException class) to the caller, which can then be used to pass a
message to the user.
public class Address implements Serializable{
.....
@PrePersist
public void validate()
if(addressLine1!=null && addressLine1.length()>1000){
throw new ValidationException("Address Line 1 is longer than 1000 chars.");
}
}
Search
Our tax registration application offered a search facility to find
details about a particular registration, its parties, and other
details. Providing an efficient search facility involved many
challenges such as writing efficient queries and implementing
pagination for browsing a large result list. JPA specifies a Java
Persistence Query Language (JP-QL) to be used with entities in order to
implement data access. It's a major improvement over EJB 2.x EJB QL. We
successfully used JP-QL to provide an efficient data access mechanism.
Queries
In JPA, we had options for creating queries dynamically or defining
static queries. These static or named queries support parameters; the
parameter values are assigned at runtime. Because the scope of our
queries was fairly well-defined, we decided to use named queries with
parameters. Named queries are also more efficient as the persistence
provider can cache the translated SQL queries for future use.
Our application provided a simple use case for this: when a user
enters an application reference number to retrieve registration
details. We provided a named query on the Registration entity as
follows:
@Entity
@Table(name="REGISTRATION")
@NamedQuery(name="findByRegNumber", query = "SELECT r FROM REGISTRATION r WHERE r.appRefNumber=?1")
public class Registration implements Serializable{
.....
}
For example, one search requirement within our application
required special attention: a report query to retrieve all the parties
with their total penalty amounts. Since the application allows parties
to exist without penalties, a simple JOIN operation wouldn't list
parties without any penalty. To overcome this, we used the OUTER JOIN
facility of JP-QL. We could also use the GROUP BY clause to add up the
penalties. We added another named query in the Party entity as follows:
@Entity
@Table(name="PARTY_DATA")
@Inheritance(strategy= InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name="PARTY_TYPE")
@NamedQueries({@NamedQuery(name="generateReport",
query=" SELECT NEW com.ssg.article.ReportDTO(p.name, SUM(pen.amount))
FROM Party p LEFT JOIN p.penalties pen GROUP BY p.name""),
@NamedQuery(name="bulkInactive",
query="UPDATE PARTY P SET p.status=0 where p.registrationID=?1")})
public abstract class Party {
.....
}
Notice in the above example of named query
"generateReport" that we have instantiated a new ReportDTO object
within the query itself. This is nonetheless a very powerful feature of
JPA.
Can We Do It in Bulk?
In our application, an officer can retrieve a registration and make
it inactive. In this case, we should set all the associated Party to
the Registration as inactive, as well. This typically means setting the
Status column in the PARTY table to 0. To improve performance, we'd use
batch updates rather than execute individual SQLs for each Party.
Fortunately, JPA provides a way to do this:
@NamedQuery(name="bulkInactive", query="UPDATE PARTY p SET p.status=0 where p.registrationID=?1")
public abstract class Party implements Serializable{
.....
}
Note: A Bulk operation issues SQL directly to the
database, which means the persistence context isn't updated to reflect
the changes. When using an extended persistence context that lasts
beyond a single transaction, cached entities may contain stale data.
Getting It Early.
Another challenging requirement was selective data display. For
example, if a manager searched for registrations, we needed to display
all the penalties that the registered parties recorded. This
information is not otherwise available to a normal caseworker. for some
registrations, we needed to display all the penalties that the
registered parties recorded. This information is not otherwise
available to a normal caseworker.
The relationship between a Party and Penalty is OneToMany. As
mentioned earlier, the default FETCH type for this is LAZY. But to meet
this search selective display requirement, it made sense to fetch the
Penalty details as a single SQL to avoid multiple SQL calls.
The FETCH Join feature in JP-QL came to our rescue. If we wanted to
temporarily override the LAZY fetch type, we could use Fetch Join.
However, if this was used frequently, it would be wise to consider
refactoring the FETCH type to EAGER.
@NamedQueries({@NamedQuery(name="generateReport",
query=" SELECT NEW com.ssg.article.ReportDTO(p.name, SUM(pen.amount))
FROM Party p LEFT JOIN p.penalties pen GROUP BY p.name""),
@NamedQuery(name="bulkInactive",
query="UPDATE PARTY P SET p.status=0 where p.registrationID=?1"),
@NamedQuery(name="getItEarly", query="SELECT p FROM Party p JOIN FETCH p.penalties")})
public abstract class Party {
.....
}
Conclusion
Overall, JPA
made coding for persistence much simpler. We found it feature-rich and
quite efficient. Its rich query interface and greatly improved query
language made it much easier to cope with complex relational scenarios.
Its inheritance support helped us sustain the logical domain model at
the persistence level and we could reuse the same entities across
layers. With all its benefits, JPA is the clear choice for the future.
Samudra Gupta
is an independent Java/J2EE Consultant in United Kingdom. He has more
than nine years of experience in building Java/J2EE applications for
public sector, retail and national security systems. He is the author
of Pro Apache Log4j (Apress, 2005) and actively contributes articles to Javaboutique, Javaworld, and Java Developers Journal. When not programming, he loves to play contract bridge and ten-pin bowling.
|