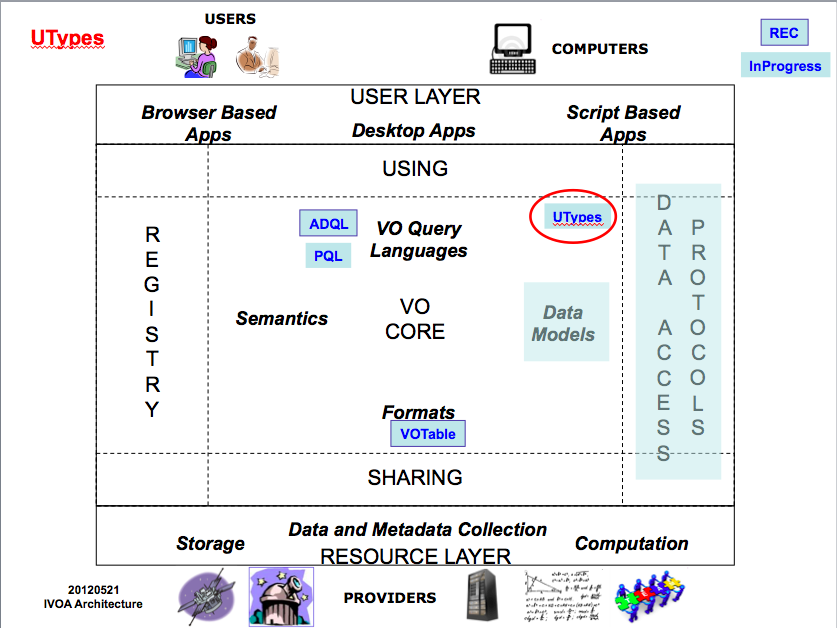
Utypes are a core part of the IVOA Architecture (see Fig. 1);
however, they currently lack a formal definition within the IVOA
(see [UTYPES] for the current state).
In spite of this, they are employed in a number of situations. The most
general usage is as an identifier for a concept defined within an
IVOA data model, i.e., a label carrying no more than nominative
semantics. A more specific usage is as a pointer (parseable
identifier) to a data model concept, semantically equivalent to a
URI or XPath in XML. There are also related practices about reuse,
inheritance, extensibility, etc.
The growing availability and usage of data models within the IVOA
— e.g., [ObsCore], [SpecDM], [STC] — and, by extension, Utypes means that a
consistent (and formal) definition is required for interoperability
as well as implementation reusability.
A survey of current usages and practices is useful input to the
definition process, both to understand what is required and what works
and does not. It is also a reference that allows one to assess the impact
of proposed solutions on current practices.
This document aims to provide such a summary.
We note that the May 2012 IVOA Working Draft on utypes [UTYPES]
presents an approach to defining utypes within a broader context of
standardizing data model definition and serialization. Utypes are
defined as data model labels that point to their associated data model
element — they are a string representation of the logical path through
the classes and attributes in a UML representation of a data model
from the main data model element to a particular part of the data
model. A generating syntax is proposed based on this premise and the
resulting usage patterns for utypes in data model (de-)serialization
described. This is, however, work in progress and does not necessarily
reflect the existing community of practice which this document seeks
to capture.
The current usages and practices regarding utypes may be presented
in several ways, e.g., by specification (VOTable, ObsCore, etc.) or by
application (TOPCAT, IRIS, etc.). One useful perspective is to
consider utypes from an IVOA Working Group standpoint, i.e., their
usages within specific subdomains of VO activity, which is the
approach we have taken in this summary. Note that we have only
considered UType references in current IVOA Recommendations as normative
— those in IVOA documents at other stages of development are potentially too
fluid and unrepresentative for this analysis and should be
considered speculative.
Unsurprisingly the bulk of usages and practices of usage arise in
the various data models defined by the DM Working Group, with most
defining utypes in tables using different conventions.
The Spectral DM 1.1 [Spectrum1.1]
defines a UType as a standard identifier for a data model
field. They are case-insensitive and of the form "a.b.c.d" where "the dots
indicate a 'has-a' hierarchy with the leftmost element being the
containing model and the rightmost element being the lowest level
element referred to". Although there are similarities with XPath,
it is stressed that the UType does not indicate the exact position of
an element in an instance but is merely a label for a data model
field. Note, however, that unique utypes within a group in a VOTable
serialization of a Spectrum "can be used to infer the data-model
structure".
An enumeration syntax is also suggested for multiple instances of
the same UType: "Data.FluxAxis.Quality.n" where n is an integer.
The Spectral data model goes on to define three serialization
formats, two of which (VOTable and FITS) link the data and metadata to
the data model using utypes. In the VOTable case, utypes are used on
RESOURCE and TABLE (both having the identical utype
spec:Spectrum) as well as FIELD and PARAM, the latter for
data model elements constant for all data points of a spectrum.
Additionally, there are GROUP elements used to "delimit data model
objects", but "nesting beyond a single GROUP is optinal, as for cases
for which the utypes are unique within a group, the utypes can be used
to infer the data model structure" (p. 57). Indeed, in the example the
utype of a parent GROUP is -- excepting what can safely be considered
editorial oversights -- always a prefix of the utypes of child GROUP,
FIELD, or PARAM elements.
The spectrum data model does not actually give stringent rules for
extending its method to other data models but notes in passing that
there were only two "tricky parts" left for further discussion. The
Spectrum DM also muses whether a type attribute on the TABLEDATA element
might be useful to make explicit that the table structure "implicitely"
represents individual points.
In its FITS serialization, the Spectral Data Model suggests a
longish map of utypes to (pre-existing or new) header keywords for
metadata -- for instance,
the FITS header ‘OBJECT’ corresponds to the
'spec:Spectrum.Target.Name' UType.
Within the metadata of columns of FITS tables, utypes are assigned
using TUTYPn header cards.
The Photometry DM 1.0 [PHOT] defines
its utypes "following the IVOA rules applied for other IVOA data
models and derived from a simplified XML schema." The form of a
UType is now "ns:a.b.c.d" where the element before the colon — 'ns'
— identifies the data model being used.
The ObsCore DM 1.0 [OBSCORE]
defines a convention that utypes created from the UML ObsCore model
follow a Camel case syntax with "attributes of a class starting with
a lower case letter." Most of obscore's concepts orginate in other
data model (Spectral, Characterization, ...), which entails some
degree of re-use that is not quite made explicit. What is said is
that for "Utypes originating from the Spectrum Data model, we keep the
original writing," which is, however, to be understood as replacing
the utype "prefix" with "obscore" (p. 35).
Utypes are not actually used in the operation of obscore services,
since all querying is performed via standardized column names. Apart
from the obvious representation in TAP_SCHEMA and the VOSI tables
endpoint, to rules or recommendations on how the utypes should be
represented in user-visible results are given.
The Characterisation DM 1.0 [CHAR]
specifies that "UTypes are built from the XML schema representation
of the model which already enforces a hierarchical structure" using
the "a.b.c.d" form. The constructed string is "based on instance
variable paths in the object-oriented data model." The difference
between this and an XPath approach is that a UType may use
"constrained element (or attribute) values in its path".
The Simulation DM 1.0 [SIM] states
that a UType is a "pointer into a data model" and that it "should
allow one to uniquely identify a concept in a data model". It notes
that it has become common practice for IVOA data models to provide a
list of utypes that they are defining. It then specifies a set of
rules for deriving utypes directly from a UML data model rather than
as a separate process:
UType := [model-UType | package-UType | class-UType |
attribute-UType | collection-UType |
reference-UType | container-UType
model-UType := <model-name>
package-UType := model-UType ":/" package-hierarchy
package-hierarchy := <package-name> ["/" <package-name>]*
class-UType := package-UType "/" <class-name>
attribute-UType := class-UType "." attribute
attribute := [primitive-attr | struct-attr]
primitive-attr := <attribute-name>
struct-attr := <attribute-name> "." attribute
collection-UType := class-UType "." <collection-name>
reference-UType := class-UType "." <reference-name>
container-UType := class-UType "." "CONTAINER"
identifier-UType := class-UType "." "ID"
In fact, all material associated with the Simulation DM is
generated from the UML model using the VO-URP framework/tool [VOURP] developed by Laurent Borges and Gerard
Lemson. A similar approach is described in the utypes Working Draft
and highlights the advantages of a common data model strategy and a
meta-model framework. Further discussion of this is outside the scope
of this document.
The Spectrum DM 1.1 implies that when data models are inherited,
utypes with the same form except for the leftmost element
(identifying the model) are equivalent: "we say that SSA inherits
the Spectrum model, so that 'SSA:' UTypes overlap with the Spectrum
ones.". An unnoted consequence of this is that the same concept
across data models must have the same 'b.c.d' identifier.
The Photometry DM seems to take this even further by using the
"Access class defined in ObsTAP and inherited from SSA" but tacking
it onto "PhotometryFilter.transmissionCurve",
viz. PhotometryFilter.transmissionCurve.Access.*. This would imply that
field names must be unique across data models.
Note, however, that the top level use of Spectrum from the Spectrum
DM must be denoted using the "spec:" namespace.
Although not actually laid out in standards documents, discussion within
the IVOA has frequently addressed user-extensability of data models and,
by extension, utypes. A simple example of how this should work is
NED SEDs that use FluxAxis.Published.Value, which is
supposed to be related to the standard
standard FluxAxis element.
Unique field names across all data models would solve part of this
problem.
SSA 1.1 [SSA] defines utypes as "pointers to
data model elements" and a mechanism
to "flatten a hierarchical data model so that all fields are
represented by fixed strings in a flat namespace." It notes,
however, that "if a data model becomes complex enough this will no
longer be possible." The standard proposes GROUP elements as a
solution but does not go into details. In the example response, there
are "flat" (one-level) GROUP elements reflecting the structure of the
utypes.
Although nothing is explicitly said about utypes being parsable,
this is certainly implied by the pseudo-grammar defined with a UType
being constructed using "embedded period characters to delimit the
fields of the UType". Utypes are defined within a single namespace
identifying the data model with the form "(component-name).(field-name)"
and are unique only within the context of the specified data model.
However, a convention is also described whereby concepts that are
common to both the Spectrum DM and the SSA query response do not
require the "spectrum." identifier when used in the SSA query
response; hence "Spectrum.Target.Name" and "Target.Name" are
to be considered equivalent in this particular context.
Utypes are also case-insensitive.
A 2011 survey of UType practices in SSA [SSASTATE] response documents showed rather
inconsistent results .
In TAP, utypes enter as columns in TAP_SCHEMA.
They can be assigned to schemas, tables, columns, and foreign keys (this is analogous
to VODataService; cf. Registry). Utypes for columns are already used by
Obscore. No further details are given on the content of the columns
containing utypes by the TAP specification, but obviously at least these
particular utypes will have to work as simple, and presumably opaque,
strings if they are to be useful in SQL queries. That foreign keys can
have utypes furthermore demonstrates that, at least for TAP, utypes not
only annotate concrete data or metadata items but also relations between
those.
Utypes were introduced as an attribute of many VOTable elements in
VOTable 1.1 [VOT1.1] (FIELD, PARAM,
FIELDref, PARAMref, RESOURCE, TABLE, and GROUP) as an identifier for
something in an external data model. They should have the form
"datamodel_identifier:role_identifier". Although the schema defines
UType to have a non-namespaced value, the VOTable REC recommends to
use "the xmlns convention which specifies the URI of the data model
cited", referring to an example along the lines of:
<VOTABLE version="1.2"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.ivoa.net/xml/VOTable/v1.2"
xmlns:stc="http://www.ivoa.net/xml/STC/v1.30" > ...
<FIELD name="RA" ID="col1" ucd="pos.eq.ra;meta.main"
ref="J2000" UType="stc:AstroCoords.Position2D.Value2.C1"
datatype="float" width="6" precision="2" unit="deg"/> ...
The IVOA Note "Referencing STC in VOTable" [VOTSTC] suggests embedding space-time coordinate
metadata in VOTables by means of references to FIELDs and PARAMs. These
references are kept in GROUPs with a defined UType. Each group should
define the data model used via a specific <prefix>:DataModel.URI
UType (which entails that the prefix is significant and
role identifiers from different data models can refer to completely
differnt concepts).
Abusing XML namespace declaration for the purpose of binding data model
names to URIs is explicitely discouraged.
The utypes themselves are defined essentially through XPaths into
STC-X instance documents, although child element and attribute names are
treated analogously (i.e., <elem attr="bla"/> and
<elem><attr>bla</attr></elem> are
not distinguished), and some special rules apply to deal with the substitution
groups of STC-X.
A short example for an STC metadata declaration might be:
<GROUP utype="stc:CatalogEntryLocation">
<PARAM name="href" datatype="char" arraysize="*"
utype="stc:AstroCoordSystem.href"
value="ivo://STClib/CoordSys#TT-ICRS-TOPO"/>
<PARAM name="URI" datatype="char" arraysize="*"
utype="stc:DataModel.URI"
value="http://www.ivoa.net/xml/STC/stc-v1.30.xsd"/>
<FIELDref ref="ra" utype="stc:AstroCoords.Position2D.Value2.C1"/>
<FIELDref ref="de" utype="stc:AstroCoords.Position2D.Value2.C2"/>
<FIELDref ref="dateObs" utype="stc:AstroCoords.Time.TimeInstant"/>
</GROUP>
Adoption of [VOTSTC] has been moderate so far.
Similar approaches combining GROUP, PARAM, and FIELDref elements have
been tried by [PHOTNOTE] for photometry. In
a related effort, prototype services have even combined utypes from
different data models in one such GROUP; at the time of writing, CDS'
VizieR service returns VOTable fragments like
<GROUP ID="gsed" name="_sed" ucd="phot" utype="spec:PhotometryPoint">
<DESCRIPTION>The SED group is made of 4 columns: mean frequency, flux,
flux error, and filter designation</DESCRIPTION>
<FIELDref ref="sed_freq"
utype="photdm:PhotometryFilter.SpectralAxis.Coverage.Location.Value"/>
<FIELDref ref="sed_flux" utype="spec:PhotometryPoint"/>
<FIELDref ref="sed_eflux" utype="spec:PhotometryPointError"/>
<FIELDref ref="sed_filter"
utype="photdm:PhotometryFilter.identifier"/>
</GROUP>
The SSAP client SPLAT (written by Peter Draper and Margarida Castro Neves)
[SPLAT] uses utypes in serveral ways.
When processing an SSA response, it tries to locate the columns
interesting to it using utypes. The approach may be illustrated by a
comment in the code that states:
The choices
are controlled by a series of regular expressions that can be extended as
needed, or by looking for the standard set of utypes defined by the IVOA
Spectral Data Model (1.0).
— which is supposed to mean that, when UType
matching fails, some heuristics are applied to guess based on column names. The
UType match here is case insensitive, and to dodge the confusing specifications
on the first few elements of a utype,
SPLAT matches what might be described as suffix patterns. Among
the UType patterns matched in this way are: access.reference, access.format,
target.name, char.spectralaxis.name, char.fluxaxis.unit, and the
like.
Within a spectrum deemed compliant to the Spectral Data Model,
SPLAT tries to locate flux and
spectral axes as well as errors and units of those using utypes. Again, the
match is case insensitive and employs suffix rules.
When processing a spectrum in VOTable format, SPLAT searches for TABLE
elements with a UType "sed:Segment" to extract the corresponding data. This
search is case sensitive, and a full match is required; the
specification that inspired that behaviour has not made it to IVOA REC
yet.
Aladin (written by Pierre Fernique and others) [ALADIN] employs utypes for:
- Finding and interpreting coordinate columns
- Recognizing data content (VOTable signature)
- Interpreting STC regions
- Interpreting DAL SIA responses
- Interpreting DAL SSA responses
The full list of utypes required for each task is given in
appendix A.
VOSpec (written by Juan Gonzalez) [VOSpec] uses utypes for:
- SSAP parsing: utypes are identified by direct string comparison of
fragments with the documented utypes, i.e., after converting the UType
found in the table to upper case, a check is made whether this UType
contains a fragment of a certain fragment of the UType defined in the specification. In case the required UType is not found, a check of UCDs and ids is also
done in some cases to cope with severely non-compliant services.
- SLAP parsing: In order to parse Simple Line Access Protocol
services (SLAP), instance documents are analyzed quite as for SSAP. In
this case, however, the comparison is done with the full utype specified
in SLAP as the services are more compliant than SSAP ones; utypes are
compared ignoring case.
- Photometry Services parsing: Same as before — direct case insensitive
string comparison.
- Spectral DM files in XML parsing: Case insensitive comparison with
utypes defined in Spectrum DM document.
In summary, VOSpec uses utypes in case insensitive string comparison.
There is no evaluation of schema URLs, utype parsing, navigation or other
advanced utype features.
TOPCAT (written by Mark Taylor) [TOPCAT]
distinguishes between three types of UType usage:
- Semantically aware usage of terms in the existing UType vocabulary/ies
- Semantically unaware manipulation of UType strings
- Places where utypes could/might/should be used but are not
The SSA "Access.Reference" utype is used to identify an initial guess
for the spectrum URL column whose contents will be passed to spectrum
viewers via SAMP when a View Spectrum activation action is selected.
When looking for the right column Utype, any prefix is ignored,
and a UType which endsWith(":Access.Reference") is preferred,
otherwise any one which endsWith("Access.Reference") is used.
Utypes are read/written in various places by the table I/O layer.
Utypes are part of STIL's internal table model, and so UType values
which are associated with columns are read in and recorded from
table formats which support utypes, and the utypes are propagated
to output tables if the output format supports that. True support
for utypes is only provided in VOTable, but STIL has an internal
convention of using TUTYPnnn header cards for FITS tables analogous to
the FITS serialization of the spectral data model. In the
case of a UType which is too long to fit in a FITS header
(>68 characters) the UType is not propagated to the output
(it is lost).
Utypes are displayed, and can be added/edited, in the TOPCAT GUI
for table columns and parameters.
One use of utypes propagated in this way is to address
table columns and parameters in algebraic
expressions using the following syntax:
The string "utype$" followed by the text of a UType identifying
the required value. Any punctuation (such as ".", ":", "-") in the
UType should be replaced with a "_" (since these symbols cannot
appear in identifiers). The first matching column, or if there is
none the first matching parameter value is returned. UType matching
is case-insensitive.
So for instance a column with the UType obscore:Target.Name
can be addressed using the expression "utype$obscore_target_name"
as an alternative to using the column name.
taplint (the TAP service validator) checks that utypes match between
TAP_SCHEMA and the /tables endpoint. It also checks that utypes are correct
for tables declaring themselves ObsCore.
The SAMP MType spectrum.load.ssa-generic requires all UCDs and utypes
to be bundled up as name/value pairs in the "meta" map. The
documentation at
http://wiki.ivoa.net/twiki/bin/view/IVOA/SampMTypes#spectrum_load_ssa_generic
says:
meta (map):
Additional metadata describing the spectral data found at
the URL. Key->Value pairs represent either utypes or UCDs as
defined or used in some version of the SSA specification or its
predecessors. Example map keys are Access.Format (SSA 1.0 MIME
type Utype) or VOX:Spectrum_Format (pre-1.0 SSA MIME type UCD). It
is up to the recipient to make sense of these and, for instance,
deal with the possibility that given expected keys are present
or that apparently contradictory information is presented. Most
existing SSA-aware spectrum viewing clients already contain this
functionality.
TOPCAT duly grabs these from table
columns and passes them on to spectrum viewers.
Finally, TOPCAT uses utypes internally when saving session state into
a VOTable. This uses private utypes in the topcat_session namespace:
- topcat_session:isTopcatModel
- topcat_session:saveVersion
- topcat_session:label
- topcat_session:columnIndices
- topcat_session:columnVisibilities
- topcat_session:broadcastRows
- topcat_session:rowSubsetFlags
These are not intended to be comprehensible to anybody but the TOPCAT
application itself.
STILTS does not allow you to set/read utypes for columns/parameters
from the command line, though it does allow you to do that for UCDs.
Probably, it should do it for utypes.
STILTS/TOPCAT allows you to do multiple SSA (and SIA) positional
searches in the same way as multiple cone searches. As a non-essential
part of this, it attempts to find the actual sky position of the returned
spectrum — if it can do that it can report on how far away the spectrum
was from the request, and also figure out which is the closest match
in the event that there are more than one within the requested radius.
So it wants to work out RA and Dec from an SSA response, though if it
fails to do it, the multi-SSA still works.
It does not use utypes for this. Here is the comment from the code:
// Could work harder here (and for getDecIndex); the correct thing
// to do for SSA 1.04 would be to look for the column with
// utype ssa:Char.SpatialAxis.Coverage.Location.Value, and interpret
// this in conjunction with other STC-like columns to make sense
// of it as an ICRS position. Two problems here: 1 - STC; 2 - the
// spatialaxis.coverage column looks like a 2-element vector (at
// least in some SSA results), so it can't have a column index.
// Would need to redefine ConeSearcher interface so it gets
// something more flexible than a column interface, or in the
// performSearch method rejig the table so that it contained some
// new columns with ICRS RA & Dec. Since I suspect SSA from
// ttools is going to be rather niche functionality, I don't think
// it's worth the effort just now.
Ad-hoc regex pattern matching on the column name is used instead.
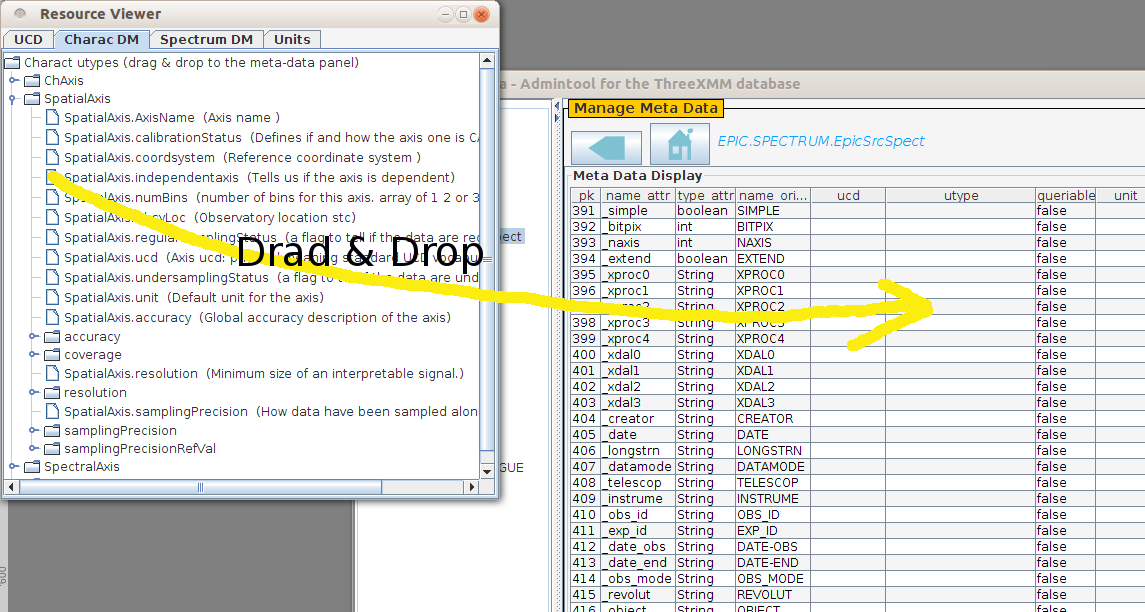
The principle of Saada [SAADA] is to
automatically ingest data files in a database. The built-in database
schema is flexible enough to allow users to load data without doing
any mapping. The consequence is that, by default, the database only
contains metadata found in input files. That is enough to build a
searchable repository, but not to build VO compliant services. For
that, native metadata must be enriched with quantities which are not
necessarily in data files: namely UCDs, units, utypes and
descriptions. These quantities can be set in metadata by a simple
drag & drop (see Fig. 2). That is very relevant for UCDs and units
which can be used to query data (e.g. [phys.veloc] > 1000 [km/s]).
Utypes can also be mapped that way but this operation remains out of
the scope of any data model.
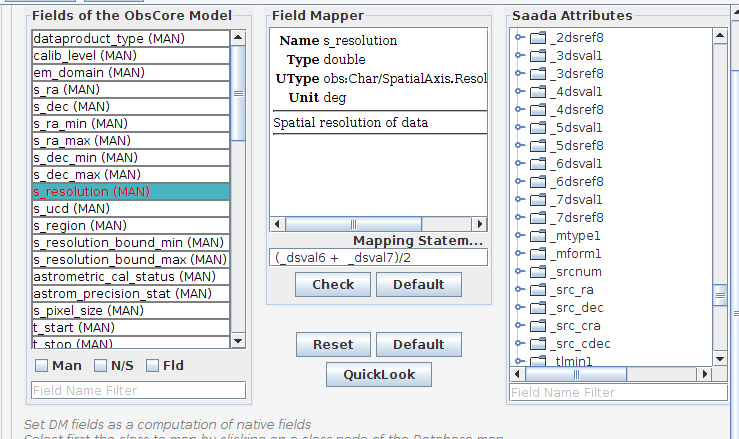
Another tool allows mapping a model on a dataset.
Saada hosts inner VO model descriptions (just ObsCore right now) and DM fields can be mapped on real data.
The mapper shown in Fig. 3 binds DM fields with arithmetic operations on database columns.
The resulting mapping expressions are used by the Saada VO interface
to format the query results in a way compliant with the DM supported
by a given service. Utypes are used here to identify DM fields. They
are considered as simple strings without regards on their inner
structure.
In the Saada query engine constrains can be expressed with utypes, quite
in analogy with UCDs.
Iris [IRIS] is designed on a stack of
abstraction layers around a common framework that allows easy
extensibility via plugins. This is realized by SEDLib which provides:
- basic SED I/O capabilities for VOTable and FITS serializations
- SEDs and Segments as first class objects, with a relatively low-level library
The library implements the Spectrum 1.03 Data Model and it is used
by components up in the framework layers ladder to abstract the
components themselves from the details of the serialization. In
particular, SEDLib implements the Data Model described by the XML
schema, which is not equivalent to the UML diagrams in the Spectrum 1.03 document, but is more suited to a concrete implementation.
Utypes are used to map the Spectra/SED VOTable metadata to the DM
implemented by SEDLib. All the UTyped values are made available by
SEDLib in a Sed class instance. Thus, users can browse all the metadata
in a more consistent way: all the values that refer to the same concept
(i.e. utypes without the prefix are the same) are displayed in the same
column in the metadata browser, and users can build boolean expressions
to filter their data. Also, all the components (either native or from
third party plugins) can programmatically access, as input/output, all
the values in the original file, thus adding science capabilities to
Iris.
The utypes prefix ("namespace") is ignored when comparing utypes,
but it is used (as "spec:") when writing out the files. Note that, in
accordance with Spectrum 1.1, only utypes with the spec prefix are
interpreted as part of the Spectrum DM, even though Spectrum 1.1
imports classes from the CharDM (prefix char), which in turn imports
STC classes (prefix stc). As a result, even though the classes, in
most cases, are the same, stc: and char: utypes are not interpreted,
unless the unprefixed utypes were the same; this is never the case for
Spectrum 1.1, because the *:Spectrum.* pattern that spoils the blind
string comparison.
Utypes are used in conjunction with UCDs for discriminating between
different spectral quantities and perform consistency checks. For
instance, when a segment’s FluxAxis represents a quantity that can’t be
converted to the quantities of the other segments in a SED, an exception
is thrown when one tries to add that segment to the SED.
Some services (notably NED) add some utypes for tagging metadata
related to the provenance of the data (e.g. the bibcode reference to
the paper whence the data has been drawn). This information is
available in SEDLib, but in order to be used (e.g. by plugins
dedicated to those services) they must be accessed using the utypes
string. In compliance with the assumption that utypes should not be
parsed, and in the absence of a proper extensibility specification, the
use of this metadata is naïve. Nonetheless, custom metadata is shown to
the user and can be used for filtering purposes.
Several changes will need to be made when Iris is updated to the
Spectral 2.0 DM: the UType namespace will change and all the Spectrum
1.1 utypes will be replicated with a different prefix: "sdm". All the
utypes in Spectrum 1.1 will be changed by removing the Spectrum string.
The VODataService 1.1 [VODS] standard allows
utypes on schemas, tables, columns, and foreign keys (this is analogous to
TAP_SCHEMA; cf. section 2.2). The UType element
is defined to be of type xs:token.
Comments in the XML schema indicate that from the point of view
of VODataService, a UType on a schema is
"an identifier for a concept in a data model that the data in
this schema as a whole represent". Utypes on a foreign key are defined
as "an identifier
for a concept in a data model that the association enabled by this key
represents", on tables as "an identifier for a concept in a data model
that the data in this table represent". In each case, VODataService
states that the "format defined in the VOTable standard is highly
recommended."
No means of associating prefixes with URIs or providing further
structure is given. Nothing is said on case normalization.
A working draft for the relational registry 2 [REGTAP] employs utypes to
- link the VOResource data model as defined by the collection of the
related XML schema documents with columns in a set of database
tables
- allow a representation of (fairly simple) VOResource extensions
without having to explicitly model all aspects of them.
Generating utypes for the RegTAP columns and tables is done via XSLT
that operates on XSD (the XSLT will fail for certain authoring ways that
do not occur in VOResource). Conceptually, 1:1 relationships are
represented by concatenating the name of the root type and the
attribute names in an XPath-like fashion, whereas for other
relationships, a referring utype (as for 1:1 relationships) and a utype
for the elements of the collection is generated.
To avoid having to redefine the table structure for every VOResource
extension newly defined, RegTAP has a table mapping pairs of resource IVORN
and UType to string values. The utypes are computed as above; the
computability is convenient since it avoids the requirement for authors
of VOResource extensions to manually define utypes.
RegTAP requires lowercasing utypes on ingestion to ensure that
case-insensitive matching is possible although ADQL has no native operator
reliably doing case-insensitive string comparisons. In other words,
RegTAP
assumes that utypes are case-insensitive.
The current VOUnits proposed recommendation mentions utypes as a tool to express "the
nature of the concept" and offer UCDs as an alternative tool; in this way
each quantity in a model would be "described with a UCD or UType, value
and VOUnit". As to what a "concept" might be, it suggests as an
example that utypes could in this way identify a
"quantity MJD [...] seen as a concept" (rather than trying to shoehorn
the time scale into a unit string).
TimeSeries representation to identify concepts in TimeSeries DM.
This works rather as discussed above for VOTables.
The specifications put forward by the Grid and Web Services Working Group
make no use or mention of utypes in any of its specifications.
The following is a redacted collection of critique that was raised to
or within the Utypes Tiger Team. That a given point is discussed here
does not necessarily mean all Tiger Team members agree that a given
issue is serious or is an issue at all, even where no concrete source is
indicated.
Probably the most common complaint is that the definition of utypes
has been at least bewildering, which lead to one and the same thing
being referred to by several utypes. Part of this results from evolving
or unclear standards; as an example, spec:Target.Name,
spec:Spectrum.Target.Name and sdm:Target.Name were, are, or will be
designations for something that has not changed in the underlying data
models.
Partly as a consequence of this, most services using utypes are
non-compliant to some degree [SSASTATE],
which again gave client implementors a hard time and lead to a variety
of practices of suffix and/or infix matching, typically not even
consistently applied even within one code base.
There has also been an expectation that when, e.g., both Obscore and
Spectral talk about, say, the DID assigned by a publisher, the utype
used by both should be identical, either with or without the prefix.
Against that has been raised that utypes are not concept labels as UCDs
but something linked to a concrete data model. With data models
different, the utypes should be different, too.
On the other hand, developers voiced a demand for consistent markup
of classes wherever they turn up; for instance, within certain versions
of the spectral data model, accuracy can be modeled as a single class
with a eight attributes. There are, however, more than a hundred utypes
matching spec:*.Accuracy.*, all eventually mapping
to these eighte attributes, which is considered wasteful by some.
Directly connected to the syntax of utypes is an uncertainty whether
the "prefix" is significant when comparing utypes or must, rather, be
ignored. It appears the intention of, e.g., the authors of SSAP and the
spectral data model has been that comparisons would in general ignore
the prefix, while the STC-in-VOTable note quite strongly indicates that
usual clients should never have to dissect the utype string. Also,
while the notion that utypes are to be compared ignoring case is at
least very widespread, discussions about specific spellings repeatedly
came up, confusing implementors.
There has also been debate on whether plain sequences of utype-value
pairs should be able to represent more complex data structures, e.g.,
ordered sequences or sequences of complex objects. This lead to
proposed syntaxes like foo.bar.n, foo.bar[n], and foo.bar[n].quux. At
least Aladin still understands some utypes formed like this, but it
seems the notion of coding complex instance structure in this way
never really caught on.
Against the proposal to annotate VOTable FIELDs using FIELDrefs from
GROUPs, some implementors objected the usage of GROUP and the ample
referencing required an application to memorize a fairly large number of
things.
Another topic of concern is the applicability of the utypes mechanism
to FITS files; a suggestion on how this might work was made in the
context of the spectral data model (see above). Against this it was
argued that for values encoded in the FITS header, an arbitrary 8-char
keyword must be mapped to a utype, where the term "arbitrary" here means
that there is no algorithmic mapping between data model roles and FITS
keywords. In the concrete example of the SDM, the relationship between
VOTable utypes and FITS keywords is also degenerate, because in
VOTables, some fields can have different values in, e.g., the Data and
Char section, while in FITS some Char fields are inherited from
Data.
A consequence of the ad-hoc nature of relating header keywords and
data model elements is that a
trivial round-tripping of compliant files by model unaware programs
spoils the compliance of the file itself. For example, if the user uses
TOPCAT to discover a SED from the NED SED service, and then saves it as
a FITS, the file is not compliant anymore. A related problem turns up when a
compliant FITS spectrum is saved to VOTable by a model-unaware
application. Note that the information loss depends on whether
certain piece of metadata is contained in a column or in a parameter
inside the header. For columns, the TUTYPn convention allows utypes to
be linked to columns, but this is not possible for header keywords.