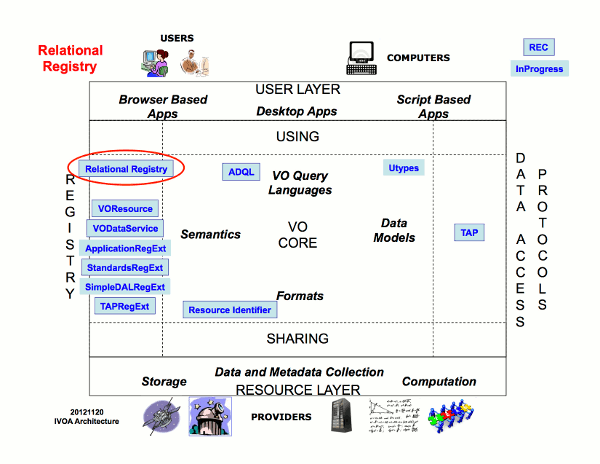
In the Virtual Observatory (VO), registries provide a means for
discovering useful resources, i.e., data and services. Individual
publishers offer the descriptions for their resources ("resource
records") in publishing registries. At the time of writing, there are
roughly 14000 such resource records active within the VO, originating
from about 20 publishing registries.
The protocol spoken by these
publishing registries, OAI-PMH, is not suitable for data discovery, and
even if it were, data discovery would at least be fairly time consuming if
each client had to query dozens or, potentially, hundreds of
publishing registries.
To enable efficient data discovery nevertheless, there are services harvesting the
resource records from the publishing registries and offering interfaces
more suitable for querying by their users. The IVOA Registry
Interfaces specification [std:RI1] defined, among other aspects of
the VO registry system, such an interface
using SOAP and an early draft of an XML-based query language.
This document provides an update to the query ("full registry") part
of this specifiation, aimed towards
usage with current VO standards, in particular TAP [std:TAP]
and ADQL [std:ADQL]. It follows the model of ObsCore
[std:OBSCORE] of defining a representation of a data model
within a relational data base. In this case, the data model is a
simplification of the VO's resource metadata interchange representation,
the VOResource XML format [std:VOR]. The simplification
yields 13 tables. This specification gives the table metadata together
with rules for how to fill these tables from VOResource-serialized
metadata records.
This architecture allows client applications to perform "canned"
queries on behalf of their user as well as complex queries formulated
directly by advanced users, using the same TAP clients they employ to
query astronomical data servers.
This specification directly relates to other VO standards in the
following ways:
- VOResource, v1.03 [std:VOR]
- VOResource sets the foundation for a formal definition of the data
model for resource records via its schema definition. This document
refers to concepts laid down there via the utypes given here.
- VODataService, v1.1 [std:VODS11]
- VODataService extends the VOResource data model by important
concepts and resource types (tablesets, data services, data
collections). These concepts and types are reflected in the database
schema. Again utypes on the tables and columns link this specification
and VODataService.
- Other Registry Extensions
- Registry extensions are VO standards
defining how particular resources (e.g., Standards) or capabilities
(e.g., IVOA defined interfaces) are described. Most aspects
introduced by them are reflected in the
res_detail table using
utypes algorithmically generated from the XML schema documents given by
these standards. This document should not in general need updates
for registry extension updates. Still, in particular with a view to the
caveat on the limits of the utypes generation algorithm given
in section 5, we note the
versions current as of this specification: SimpleDALRegExt 1.0
[std:DALREGEXT],
StandardsRegExt 1.0 [std:STDREGEXT], TAPRegExt 1.0
[std:TAPREGEXT], Registry Interfaces 1.0 [std:RI1].
- TAP, v1.0 [std:TAP]
- The queries against the schema defined here, and the results of
these queries, will usually be transported using the Table Access
Protocol TAP. It also allows discovering
local additions to the registry relations via TAP's metadata publishing
mechanisms.
IVOA Identifiers, v1.12 [std:VOID]
IVOA identifiers are something like the
primary keys within the VO registry. Also, the notion of an authority as
laid down in IVOA Identifiers plays an important role as publishing
registries can be viewed as a realization of a set of authorities.
This standard also relates to other IVOA standards:
- ADQL, v2.0 [std:ADQL]
- The rules for ingestion are designed to allow
easy queries given the constraints of ADQL 2.0. Also,
we give three functions that extend ADQL using the
language's built-in facility for user-defined functions.
- utypes
- To link columns and tables in the relational resource model to
entities defined in VOResource and ancillary specifications, we employ
utypes; as of this writing, no IVOA recommendation conclusively
defines utypes. It is expected that a Recommendation on utypes will
tie building them to a formal data model definition in a language much
simpler than XML schema. Since our data model comes in XML schema,
we need custom rules.
RegTAP-STC
This specification is complemented by a schema of four tables, also
under the rr schema, that gives coverages of resources on the spatial,
temporal, spectral and redshift axes. These will be defined in a
separate document.
In the design of the tables, the goal has been to preserve as much of
VOResource and its extensions, including the element names, as
possible.
An overriding consideration has been, however, to make natural joins
between the tables behave usefully, i.e., to actually combine rows
relevant to the same entity (i.e., resource, table, capability, etc.).
To disambiguate column names that name the same concept on different
entities (name, description, etc.) and would therefore interfere with
the natural join, a shortened tag for the source object
is prepended to the name. Thus, a description element within
a resource ends up in a column named
res_description, whereas the same element from a
capability becomes cap_description.
Furthermore, camel-case identifiers have been converted to
underscore-separated ones (thus, standardId becomes
standard_id) to have all-lowercase column names; this saves
potential headache if users choose to reference the columns using SQL
delimited identifiers. Dashes in VOResource attribute names are
converted to underscores, too, with the exception of
ivo-id, which is just rendered ivoid.
Another design goal of this specification has been that different registries
operating on the same set of registry records will return identical responses
for most queries; hence, we try to avoid relying on features left not
defined by ADQL (e.g., the case sensitivity of string matches). However,
with a view to non-uniform support for information retrieval-type
queries in database systems, the ivo_hasword user defined
function is not fully specified here; queries employing it may yield
different results on different implementations, even if they operate on
the same set of resource records.
This specification piggybacks on top of the well-established
VOResource standard. It explicitly does not define a full data model,
but rather something like a reasonably query-friendly view of a partial
representation of one. The link between the actual data model, i.e.,
VOResource and extensions as defined by the XML Schema documents, and
the fields within this database schema, is provided by
utypes.
These utypes are generated from the XML schema files
for VOResource and its extensions by means of an XSL stylesheet.
They are intended to be compatible
with the utypes generated according to a future IVOA specification.
These are expected to be based on a modelling
language called VO-DML; since VOResource is not modelled in VO-DML — and
probably never will, since interoperability with other OAI-PMH
applications makes XML Schema a compelling choice as the modelling
language —, we have to provide some custom method to define utypes and
their relation to modelling elements
The basic premise here is that 1:1 relationships are mapped to utypes
by concatenating type and attribute names until the leaf element is
reached; attributes and elements (in XSD terms) are not distinguished.
1:n relationships yield one utype for the attribute (the "collection
utype", which is used on some tables), while utypes for the elements of
the collection are rooted in the collection element's types. For
example, the capabilities of a service have the collection utype
vr:Service.capability, but the standard identifier of a
capability has the utype vr:Capability.standardID.
XML namespaces are ignored in utype generation. In particular, the
xsi:type attributes that provide polymorphism for VOResource's
Resource and Capability elements yield
utypes ending in type, as in vr:Resource.type and
vr:Capability.type.
At the utype level, polymorphism is reflected by using the names of the
type definitions in which an element or attribute is defined as a utype
fragment. For
example, in the description of a single data collection there can be
values for vr:Resource.created (as the definition of
the created attribute is on vr:Resource
itself) as well as vs:DataCollection.instrument (since
instrument comes from the definition of the XML Schema
DataCollection type in this case).
The data model name of the utypes, i.e., the part in front of the
colon, is the canonical target name space prefix taken from the XML
schema. The remarks on versioning those from section 4 apply here as well.
An XSLT stylesheet producing utypes together with short
documentation strings from the XML schema files is given in Appendix
A. Note that due to limitations of XSLT version 1, the complexity
of XML schema, as well as considerations of implementation simplicity,
this stylesheet is not completely general (see also comments in the
file). Future VOResource extensions could break it if, e.g., they were
to inherit from types derived from vr:Resource in a
different file. As given here, the stylesheet produces the desired
results for the versions of VOResource and its extensions given in
section 1.1.
Note that for readability utypes are given in camel-case
throughout the normative text of this document,
following the XML Schema names. However, utypes are generally
considered to be case insensitive. Hence, in the database tables, all
utypes are stored all-lowercase; this is mandated by the case conversion
rules in the table descriptions.
In the following table descriptions, names and utypes of tables and
columns are normative and MUST be used as given, and all-lowercase.
Descriptions are not normative (as given, they usually are taken from
the schema files of VOResource and its extensions with slight
redaction). Registry operators MAY provide additional columns in their
tables, but they MUST provide all columns given in this
specification.
All table descriptions start out with brief remarks on the
relationship of the table to the VOResource XML data model. Then, the
columns are described in a selection of TAP_SCHEMA metadata. For each
table, recommendations on explicit primary and foreign keys as well as
indexed columns are given, where it is understood that primary and
foreign keys are already indexed in order to allow efficient joins;
these parts are not normative, but operators should ensure decent
performance for queries assuming the presence of the given indices and
relationships. Finally, lowercasing requirements
(normative) are given.
The following tables make up the data model
ivo://ivoa.net/std/RegTAP/vor:
Table
Utype | Description |
|---|
rr.capability
vr:Service.capability | Pieces of behaviour of a resource. |
rr.interface
vr:Interface | Information on access modes of a capability. |
rr.intf_param
vs:InputParam | Input parameters for services. |
rr.relationship
vr:Resource.content.relationship | Relationships between resources, e.g., mirroring, derivation, but
also providing access to data within a resource. |
rr.res_date
vr:Resource.curation.date | A date associated with an event in the life cycle of the resource.
This could be creation or update. The role column can be used to
clarify. |
rr.res_detail
N/A | Utype-value pairs for members of resource or capability and their
derivations that are less used and/or from VOResource extensions. The
pairs refer to a resource if cap_index is NULL, to the referenced
capability otherwise. |
rr.res_role
N/A | Entities, i.e., persons or organizations, operating on resources:
creators, contacts, publishers. |
rr.res_schema
vs:TableSchema | Sets of tables related to resources. |
rr.res_table
vs:Table | (Relational) tables that are part of schemata or resources. |
rr.resource
vr:Resource | The resources, i.e., services, data collections, organizations, etc.,
present in this registry. |
rr.subject
vr:Resource.content.subject | Topics, object types, or other descriptive keywords about the
resource. |
rr.table_column
vs:Table.column | Metadata on columns of tables pertaining to resources. |
rr.validation
N/A | Validation levels for resources and capabilities. |
The rr.resource table contains most atomic members of
vr:Resource that have a 1:1 relationship to the resource
itself. Members of derived types are, in general, handled through
the res_detail
table even if 1:1 (see 7.13). The
content_level, waveband, and rights members are 1:n but still appear
here. If there are multiple values, concatenate them with hash
characters (#). Use the ivo_hashlist_has ADQL extension
function to check for the presence of a single value. This convention
saves on tables while not complicating common queries significantly.
A local addition is the creator_seq column. It contains
all content of the name elements below a resource element
curation child's creator children,
concatenated with a sequence of semicolon and blank characters (";
"). The individual parts must be concatenated preserving the
sequence of the XML elements. The resulting string is primarily intended
for display purposes ("author list") and is hence not case-normalized.
It was added since the equivalent of an author list is expected to be
a metadatum that is displayed fairly frequently, but also since the
sequence of author names is generally considered significant. The
res_role table, on the other hand, does not allow
recovering the input sequence of the rows belonging to one resource.
The res_type column reflects the lower-cased value of
the ri:Resource element's xsi:type attribute,
where the canonical prefixes are used. While custom or experimental
VOResource extensions may lead to more or less arbitrary strings in that
column, here is an enumeration of res_types from the
VOResource and its IVOA-recommended extensions at the time of
writing, together with explanations taken from the schema files and
comments.
- vg:authority
- A naming authority (these records allow resolving who is responsible
for IVORNs with a certain authority; cf. [std:VOID])
- vg:registry
- A registry is considered a publishing registry if it contains a
capability element with
xsi:type="vg:Harvest". Old,
RegistryInterface 1-compliant registries also use this type with a
capability of type vg:Search. The relational registry as
specified here, while superceding these old vg:Search
capabilities, does not use this type any more. See section
6 on how to locate services
supporting it.
- vr:organisation
- The main purpose of an organisation as a registered resource is to
serve as a publisher of other resources.
- vr:resource
- Any entity or component of a VO application that is describable and
identifiable by a IVOA Identifier; while it is technically possible to
publish such records, the authors of such records should probably be
asked to use a more specific type.
- vr:service
- A resource that can be invoked by a client to perform some action on
its behalf
- vs:catalogservice
- A service that interacts with one or more specified tables having
some coverage of the sky, time, and/or frequency.
- vs:dataservice
- A service for accessing astronomical data; publishers choosing
this over
vs:catalogservice probably intend to communicate
that there are no actual sky positions in the tables exposed.
- vs:datacollection
- A schema as a logical grouping of data which, in general, is
composed of one or more accessible datasets. Use the
rr.relationship table to find out services that allow
access to the data (the served_by relation), and/or look for values for
vs:datacollection.accessurl in
rr.res_detail.
- vstd:standard
- A description of a standard specification.
The status attribute of vr:Resource is
considered an implementation detail of the XML serialization and is not
kept here. Neither inactive nor deleted
records may be kept in the resource table. Since all
other tables in the relational registry should keep a foreign key on the
ivoid column, this implies that only metadata on
active records
is being kept in the relational registry. In other words, users can
expect a resource to exist and work if they find it in a relational
registry .
Name
Utype | Type | Description |
|---|
ivoid
vr:Resource.identifier | adql:VARCHAR(*) | Unambiguous reference to the resource conforming to the IVOA standard for identifiers |
res_type
vr:Resource.type | adql:VARCHAR(*) | Resource type (something like vs:datacollection, vs:catalogservice, etc) |
created
vr:Resource.created | adql:TIMESTAMP | The UTC date and time this resource metadata description was created. This timestamp must not be in the future. This time is not required to be accurate; it should be at least accurate to the day. Any insignificant time fields should be set to zero. |
short_name
vr:Resource.shortName | adql:VARCHAR(*) | A short name or abbreviation given to something. This name will be used where brief annotations for the resource name are required. Applications may use to refer to this resource in a compact display. One word or a few letters is recommended. No more than sixteen characters are allowed. |
res_title
vr:Resource.title | adql:VARCHAR(*) | The full name given to the resource |
updated
vr:Resource.updated | adql:TIMESTAMP | The UTC date this resource metadata description was last updated. This timestamp must not be in the future. This time is not required to be accurate; it should be at least accurate to the day. Any insignificant time fields should be set to zero. |
content_level
vr:ContentLevel | adql:VARCHAR(*) | Description of the content level or intended audience |
res_description
vr:Resource.content.description | adql:VARCHAR(*) | An account of the nature of the resource. |
reference_url
vr:Resource.content.referenceURL | adql:VARCHAR(*) | URL pointing to a human-readable document describing this resource. |
creator_seq
vr:Creator.name | adql:VARCHAR(*) | The creator(s) of the resource in the order given by the resource record author. |
content_type
vr:Resource.content.type | adql:VARCHAR(*) | Nature or genre of the content of the resource |
source_format
vr:Resource.content.source.format | adql:VARCHAR(*) | The format of source_value. Recognized values include "bibcode", referring to a standard astronomical bibcode (http://cdsweb.u-strasbg.fr/simbad/refcode.html). |
source_value
vr:Resource.content.source | adql:VARCHAR(*) | A bibliographic reference from which the present resource is derived or extracted. |
version
vr:Resource.curation.version | adql:VARCHAR(*) | Label associated with creation or availablilty of a version of a resource. |
region_of_regard
vr:Resource.coverage.regionOfRegard | adql:REAL | A single numeric value representing the angle, given in decimal degrees, by which a positional query against this resource should be "blurred" in order to get an appropriate match. |
waveband
vs:Waveband | adql:VARCHAR(*) | A hash-separated list of regions of the electro-magnetic spectrum that the resource's spectral coverage overlaps with. |
rights
vr:Rights | adql:VARCHAR(*) | Information about rights held in and over the resource. |
This table should have the ivoid column explicitly set
as its primary key.
The following columns MUST be lowercased during ingestion:
ivoid, res_type, content_level,
content_type, source_format,
waveband.
Clients are advised to query the res_description and
res_title columns
using the the ivo_hasword function, and to use
ivo_hashlist_has on content_level,
waveband, and rights.
This table subsumes the contact, publisher, contributor,
and creator members of the
VOResource data model. They have been combined into a single table to
reduce the total number of tables, and also in anticipation of a unified
data model for such entities in future versions of VOResource.
The actual role is given in the base_role column, which
can be one of contact, publisher, contributor, or
creator. Depending on this value, here are the utypes
for the table fields (we have abbreviated
vr:Resource.curation.publisher
as Rcp, vr:Contact as Co, vr:Creator as Cr,
and vr:ResourceName as R):
| base_role value |
contact |
publisher |
creator |
contributor |
|---|
| role_name |
Co.name |
Rcp |
Cr.name |
R |
| role_ivoid |
Co.name.ivoid |
Rcp.ivoid |
Cr.name.ivoid |
R.ivoid |
| address |
Co.address |
N/A |
N/A |
N/A |
| email |
Co.email |
N/A |
N/A |
N/A |
| telephone |
Co.telephone |
N/A |
N/A |
N/A |
| logo |
Co.logo |
N/A |
Cr.logo |
N/A |
Not all columns are available for each role type in VOResource. For
example, contacts have no logo, and creators no telephone members.
Unavailable metadata MUST be represented with NULL values in the
corresponding columns.
Note that, due to current practice in the VO, it is not easy to
predict what role_name will contain; it could be a single
name, where again the actual format is unpredictable
(full first name, initials in front or behind, or
even a project name), but it could as well be a full author list. Thus,
when matching against role_names, you will have to use
rather lenient regular expressions. Changing this, admittedly
regrettable, situation would
probably require a change in the VOResource schema.
Name
Utype | Type | Description |
|---|
ivoid
vr:Resource.identifier | adql:VARCHAR(*) | The parent resource. |
role_name
N/A | adql:VARCHAR(*) | The real-world name or title of a person or organization |
role_ivoid
N/A | adql:VARCHAR(*) | An IVOA identifier of a person or organization |
address
N/A | adql:VARCHAR(*) | A mailing address for a person or organization |
email
N/A | adql:VARCHAR(*) | An email address the entity can be reached at |
telephone
N/A | adql:VARCHAR(*) | A telephone number the entity can be reached at |
logo
N/A | adql:VARCHAR(*) | URL pointing to a graphical logo, which may be used to help identify the entity |
base_role
N/A | adql:VARCHAR(*) | The role played by this entity; this is one of contact, publisher, and creator |
The ivoid column should be an explicit foreign key into
the resource table. It is recommended to maintain indexes
on at least the role_name column, ideally in a way that
supports regular expressions.
The following columns MUST be lowercased during ingestion:
ivoid, role_ivoid,
base_role.
Clients are advised to query the remaining columns, in particular
role_name,
case-insensitively, e.g., using ivo_nocasematch.
Since subject queries are expected to be frequent and perform relatively
complex checks (e.g., resulting from thesaurus queries in the clients), the
subjects are kept in a separate table rather than being hash-joined like other
string-like 1:n members of resource.
Name
Utype | Type | Description |
|---|
ivoid
vr:Resource.identifier | adql:VARCHAR(*) | The parent resource. |
subject
xs:token | adql:VARCHAR(*) | Topics, object types, or other descriptive keywords about the resource. |
The ivoid column should be an explicit foreign key into
resource. It is recommended to index the
subject column, preferably in a way that allows to process
case-insensitive and pattern queries using the index.
The ivoid column MUST be lowercased during
ingestion. Clients are advised query the subject column
case-insensitively, e.g., using ivo_nocasematch.
The capability table describes the capabilities of a resource; it only
contains the members of the base type vr:Capability.
Members of derived types are kept in the res_detail table
(see 7.13).
The table has an
integer-typed column cap_index to disambiguate multiple
capabilities on a single resource. Operators are free to choose the
actual values as convenient, although it is recommended to just
enumerate the capabilities in their physical sequence per-resource.
Name
Utype | Type | Description |
|---|
ivoid
vr:Resource.identifier | adql:VARCHAR(*) | The parent resource. |
cap_index
N/A | adql:SMALLINT | Running number of this capability within the resource. |
cap_type
vr:Capability.type | adql:VARCHAR(*) | The type of capability covered here. |
cap_description
vr:Capability.description | adql:VARCHAR(*) | A human-readable description of what this capability provides as part of the over-all service |
standard_id
vr:Capability.standardID | adql:VARCHAR(*) | A URI for a standard this capability conforms to. |
This table should have an explicit primary key made up of
ivoid and cap_index.
The ivoid column should be
an explicit foreign key into resource.
It is recommended to maintain indexes on at least the
cap_type and standard_id columns.
The following columns MUST be lowercased during ingestion:
ivoid, cap_type, standard_id.
Clients are advised to query the cap_description column
using the ivo_hasword function.
The res_schema table corresponds to VODataService's
schema element. It has been renamed to avoid clashes with
the SQL reserved word SCHEMA.
The table has an integer-typed column schema_index
to disambiguate multiple schema elements on a single resource.
Operators are free to choose the actual values as convenient, although
it is recommended to just enumerate the schema elements in their
physical sequence per-resource.
Name
Utype | Type | Description |
|---|
ivoid
vr:Resource.identifier | adql:VARCHAR(*) | The parent resource. |
schema_index
N/A | adql:SMALLINT | A running number for the res_schema rows belonging to a resource. |
schema_description
vs:TableSchema.description | adql:VARCHAR(*) | A free text description of the tableset explaining in general how all of the tables are related. |
schema_name
vs:TableSchema.name | adql:VARCHAR(*) | A name for the set of tables. |
schema_title
vs:TableSchema.title | adql:VARCHAR(*) | A descriptive, human-interpretable name for the table set. |
schema_utype
vs:TableSchema.utype | adql:VARCHAR(*) | An identifier for a concept in a data model that the data in this schema as a whole represent. |
This table should have an explicit primary key made up of
ivoid and schema_index. The
ivoid column should be an explicit foreign key into
resource.
The following columns MUST be lowercased during ingestion:
ivoid, schema_name, schema_utype.
Clients are advised to query the schema_description
and schema_title columns
using the the ivo_hasword function.
The res_table table models VODataService's
table element. It has been renamed to avoid name clashes
with the SQL reserved word TABLE.
The table contains an integer-typed column table_index to
disambiguate multiple tables on a single resource. Operators are free to
choose the actual values as convenient, although it is recommended to just
enumerate the tables in their physical sequence per-resource (but not per
schema—table_index MUST be unique within a resource).
Name
Utype | Type | Description |
|---|
ivoid
vr:Resource.identifier | adql:VARCHAR(*) | The parent resource. |
schema_index
N/A | adql:SMALLINT | Index of the schema this table belongs to, if it belongs to a schema (otherwise NULL). |
table_description
vs:Table.description | adql:VARCHAR(*) | A free-text description of the table's contents |
table_name
vs:Table.name | adql:VARCHAR(*) | The fully qualified name of the table. This name should include all catalog or schema prefixes needed to distinguish it in a query. |
table_index
N/A | adql:INTEGER | An artificial counter for the tables belonging to a resource |
table_title
vs:Table.title | adql:VARCHAR(*) | A descriptive, human-interpretable name for the table |
table_type
vs:Table.type | adql:VARCHAR(*) | A name for the role this table plays. Recognized values include "output", indicating this table is output from a query; "base_table", indicating a table whose records represent the main subjects of its schema; and "view", indicating that the table represents a useful combination or subset of other tables. Other values are allowed. |
table_utype
vs:Table.utype | adql:VARCHAR(*) | An identifier for a concept in a data model that the data in this table as a whole represent. |
This table should have an explicit primary key made up of
ivoid and table_index. The pair
ivoid, schema_index should be an explicit
foreign key into res_schema. It is recommended to
maintain an index on at least the table_description
column, ideally one suited for queries with ivo_hasword.
The following columns MUST be lowercased during ingestion:
ivoid, table_name, table_type,
table_utype.
Clients are advised to query the table_description
and table_title columns
using the the ivo_hasword function.
The table_column table models the content of VOResource's
column element. The table has been renamed to avoid
a name clash with the SQL reserved word COLUMN.
Since it is expected that queries for column properties will be
fairly common in advanced queries, it is the column table that has the
unprefixed versions of common member names (name, description, ucd,
utype, etc).
The flag column contains a concatenation of all values
of a column element's flag children, separated
by hash characters. Use the ivo_hashlist_has function in
queries against flag.
The table_column table also includes information from
VODataService's data type concept. VODataService 1.1 includes several type
systems (VOTable, ADQL, Simple). The
typesystem column contains the value of the column's
datatype child, with the VODataService XML prefix fixed
to vs; hence, this column will contain one of NULL,
vs:TAPType,
vs:SimpleDataType, and vs:VOTableType.
Name
Utype | Type | Description |
|---|
ivoid
vr:Resource.identifier | adql:VARCHAR(*) | The parent resource. |
table_index
N/A | adql:INTEGER | An artificial counter for the tables belonging to a resource |
description
vs:BaseParam.description | adql:VARCHAR(*) | A free-text description of the column's contents. |
name
vs:BaseParam.name | adql:VARCHAR(*) | The name of the column. |
ucd
vs:BaseParam.ucd | adql:VARCHAR(*) | A unified content descriptor that describes the scientific content of the parameter. |
unit
vs:BaseParam.unit | adql:VARCHAR(*) | The unit associated with all values in the column. |
utype
vs:BaseParam.utype | adql:VARCHAR(*) | An identifier for a role in a data model that the data in this column represents. |
std
vs:TableParam.std | adql:SMALLINT | If 1, the meaning and use of this parameter is reserved and defined by a standard model. If 0, it represents a database-specific parameter that effectively extends beyond the standard. |
datatype
vs:DataType | adql:VARCHAR(*) | The type of the data contained in the column. |
extended_schema
vs:DataType.extendedSchema | adql:VARCHAR(*) | An identifier for the schema that the value given by the extended attribute is drawn from. |
extended_type
vs:DataType.extendedType | adql:VARCHAR(*) | The data value represented by this type can be interpreted as of a custom type identified by the value of this attribute. |
arraysize
vs:DataType.arraysize | adql:VARCHAR(*) | The shape of the array that constitutes the value. |
delim
vs:DataType.delim | adql:VARCHAR(*) | The string that is used to delimit elements of an array value when arraysize is not '1'. |
type_system
vs:DataType.type | adql:VARCHAR(*) | The type system used, as a QName with a canonical prefix; this will ususally be one of vs:SimpleDataType, vs:VOTableType, and vs:TAPType. |
flag
vs:TableParam.flag | adql:VARCHAR(*) | hash-separated keywords representing traits of the column. Recognized values include "indexed", "primary", and "nullable". |
The pair ivoid, table_index should be an
explicit foreign key into res_table. It is recommended to
maintain indexes on at least the description,
name, ucd, and utype columns,
where the index on description should ideally be able
to handle queries using ivo_hasword.
The following columns MUST be lowercased during ingestion:
ivoid, name, ucd,
utype, datatype, type_system.
Clients are advised to query the description
column using the ivo_hasword function, and to query
the flag column using the ivo_hashlist_has
function.
The interface table subsumes both the
vr:Interface and vr:accessURL types from
VOResource. The integration of accessURL into
the interface table means that an interface in the
relational registry can only have one access URL, where in VOResource it
can have many. In practice, this particular VOResource capability has
not been used by registry record authors. Since access URLs are
probably the item most queried for, it seems warranted to save one
indirection when querying for them.
Should interfaces with multiple access URLs come into use in
the future, we propose a slight denormalization by creating mulitple
interfaces with one access URL each within the registry's ingestion
logic.
The table contains an
integer-typed column intf_index to disambiguate multiple
interfaces of one resource. Operators are free to choose the
actual values as convenient, although it is recommended to just
enumerate the interfaces in their physical sequence per resource.
Note that StandardsRegExt records can contain interface elements
outside of capabilities; therefore, intf_index runs over
resources, and the otherwise natural foreign key (ivoid,
cap_index) into the
capability table cannot be used.
Analogous to resource.res_type, the
intf_type column contains type names; VOResource extensions
can define new types here, but at the time of writing, the following
types are mentioned in IVOA-recommended schemata:
- vs:paramHTTP
- A service invoked via an HTTP query with either form-urlencoded or
multipart form-data parameters.
- vr:WebBrowser
- A (form-based) interface intended to be accessed interactively by a
user via a web browser.
- vg:OAIHTTP
- A standard OAI PMH interface using HTTP queries with form-urlencoded
parameters.
- vg:OAISOAP
- A standard OAI PMH interface using a SOAP Web Service
interface.
- vr:WebService
- A Web Service that is describable by a WSDL document.
Name
Utype | Type | Description |
|---|
ivoid
vr:Resource.identifier | adql:VARCHAR(*) | The parent resource. |
cap_index
N/A | adql:SMALLINT | The index of the parent capability; may be NULL for interfaces in resource (e.g., StandardsRegExt) |
intf_index
N/A | adql:SMALLINT | A running number for the interfaces of a resource. |
intf_type
vr:Interface.type | adql:VARCHAR(*) | The type of the interface (WebBrowser, ParamHTTP, etc). |
intf_role
vr:Interface.role | adql:VARCHAR(*) | A tag name the identifies the role the interface plays in the particular capability. If the value is equal to "std" or begins with "std:", then the interface refers to a standard interface defined by the standard referred to by the capability's standardID attribute. |
std_version
vr:Interface.version | adql:VARCHAR(*) | The version of a standard interface specification that this interface complies with. When the interface is provided in the context of a Capability element, then the standard being refered to is the one identified by the Capability's standardID element. |
query_type
vs:ParamHTTP.queryType | adql:VARCHAR(*) | The type of HTTP request, either GET or POST. |
result_type
vs:ParamHTTP.resultType | adql:VARCHAR(*) | The MIME type of a document returned in the HTTP response. |
wsdl_url
vr:WebService.wsdlURL | adql:VARCHAR(*) | The location of the WSDL that describes this Web Service. If not provided, the location is assumed to be the accessURL with '?wsdl' appended. |
url_use
vr:AccessURL.use | adql:VARCHAR(*) | A flag indicating whether this should be interpreted as a base URL, a full URL, or a URL to a directory that will produce a listing of files. |
access_url
vr:AccessURL | adql:VARCHAR(*) | The URL at which the interface is found. |
This table should have ivoid as an explicit foreign key into
resource, and the pair ivoid, and
intf_index as an explicit primary key. The pair
ivoid, cap_index is frequently used in joins
with the capability table and hence should be indexed. Additionally, it
is recommended to maintain an index on at least the
intf_type column.
The following columns MUST be lowercased during ingestion:
ivoid, intf_type, intf_role,
std_version, query_type,
result_type, url_use.
The intf_param table keeps information on the parameters
avalailable on interfaces. It is therefore closely related to
table_column, but the differences between the two are
significant enough to warrant a separation between the two tables.
Since the names of common column attributes are used where applicable in
both tables (e.g., name, ucd, etc), the two tables cannot be (naturally)
joined.
Name
Utype | Type | Description |
|---|
ivoid
vr:Resource.identifier | adql:VARCHAR(*) | The parent resource. |
intf_index
N/A | adql:SMALLINT | A running number for the interfaces of a resource. |
description
vs:BaseParam.description | adql:VARCHAR(*) | A free-text description of the column's contents. |
name
vs:BaseParam.name | adql:VARCHAR(*) | The name of the column. |
ucd
vs:BaseParam.ucd | adql:VARCHAR(*) | A unified content descriptor that describes the scientific content of the parameter. |
unit
vs:BaseParam.unit | adql:VARCHAR(*) | The unit associated with all values in the column. |
utype
vs:BaseParam.utype | adql:VARCHAR(*) | An identifier for a role in a data model that the data in this column represents. |
std
vs:InputParam.std | adql:SMALLINT | If 1, the meaning and use of this parameter is reserved and defined by a standard model. If 0, it represents a database-specific parameter that effectively extends beyond the standard. |
datatype
vs:DataType | adql:VARCHAR(*) | The type of the data contained in the column. |
extended_schema
vs:DataType.extendedSchema | adql:VARCHAR(*) | An identifier for the schema that the value given by the extended attribute is drawn from. |
extended_type
vs:DataType.extendedType | adql:VARCHAR(*) | The data value represented by this type can be interpreted as of a custom type identified by the value of this attribute. |
use_param
vs:InputParam.use | adql:VARCHAR(*) | An indication of whether this parameter is required to be provided for the application or service to work properly. |
The pair
ivoid, intf_index
should be an explicit foreign key into interface.
The remaining requirements and conventions are as per
section 7.7
where applicable.
The relationship element is a slight denormalization of the
vr:Relationship type: Whereas in VOResource, a single
relationship element can take several IVORNs, in the relational model,
the pairs are stored directly. It is straightforward to translate
between the two representations in the database ingestor.
For convenicence, we repeat the definition of the validation
levels from [std:RM]:
Name
Utype | Type | Description |
|---|
ivoid
vr:Resource.identifier | adql:VARCHAR(*) | The parent resource. |
relationship_type
vr:Relationship.relationshipType | adql:VARCHAR(*) | The named type of relationship; this can be mirror-of, service-for, served-by, derived-from, related-to, or something user-defined. |
related_id
vr:Relationship.relatedResource.ivoId | adql:VARCHAR(*) | The URI form of the IVOA identifier for the resource refered to. |
related_name
vr:Relationship.relatedResource | adql:VARCHAR(*) | The name of resource that this resource is related to. |
The
ivoid column should be an explicit foreign key into the
resoure table. You should index at least the
related_id column.
The following columns MUST be lowercased during ingestion:
ivoid, relationship_type,
related_id.
The validation subsumes the
vr:validationLevel members of both vr:Resource
and vr:Capability.
If the cap_index column in NULL the
validation comprises the entire resource. Otherwise, only the
referenced capability has been validated.
While it is recommended that harvesters only accept resource records
from their originating registries, rows in the validation table could very
well originate from third-party registries. Hence, rows in
rr.validation for the same resource might originate from
completely different registries. This can trigger potentially
problematic behaviour when the original registry updates its resource
record in that naive implementations will lose all third-party
validation rows; also, the semantics of validation results over updates
of resources and/or resource records is not fully mapped to VOResource.
Implementations are free to handle or ignore validation results as they
see fit, and they may add validation results of their own.
Name
Utype | Type | Description |
|---|
ivoid
vr:Resource.identifier | adql:VARCHAR(*) | The parent resource. |
validated_by
vr:Validation.validatedBy | adql:VARCHAR(*) | The IVOA ID of the registry or organisation that assigned the validation level. |
level
vr:Validation.validationLevel | adql:SMALLINT | A numeric grade describing the quality of the resource description, when applicable, to be used to indicate the confidence an end-user can put in the resource as part of a VO application or research study. |
cap_index
N/A | adql:SMALLINT | If non-NULL, the validation only refers to the the capability referenced here. |
The
ivoid should be an explicit foreign key into resource.
Note, however, that ivoid, cap_index is
not a foreign key into capability since
cap_index may be NULL (in case the validation
addresses the entire resource).
The following columns MUST be lowercased during ingestion:
ivoid, validated_by.
The res_date table contains information gathered from
vr:Curation's date children.
Name
Utype | Type | Description |
|---|
ivoid
vr:Resource.identifier | adql:VARCHAR(*) | The parent resource. |
date_value
vr:Date | adql:TIMESTAMP | A date associated with an event in the life cycle of the resource. |
value_role
vr:Date.role | adql:VARCHAR(*) | A string indicating what the date refers to, e.g., created, availability, updated. |
The ivoid column should be an explicit foreign key into
resource.
The following columns MUST be lowercased during ingestion:
ivoid, value_role.
The res_detail table is RegTAP's primary means for
extensability as well as a fallback for less-used simple
metadata. Conceptually, it stores triples of resource entity references, utypes,
and values, where resource entities can be resource records themselves
or capabilities. Thus, metadata with values that are either
string-valued or sets of strings can be represented in this table.
As long as the metadata that needs to be represented in the
relational registry for new VOResource extensions is simple enough, no changes to the schema defined
here will be neccessary as these are introduced. Instead, the extension itself simply defines
new utypes to be added in res_detail.
Some complex metadata—tr:languageFeature or
vstd:key being examples—cannot be kept in this table.
If a representation of such information in the relational registry is
required, this standard will need to be changed.
Appendix B gives a list
of utypes from the registry extensions
that were recommendations at the time of writing.
Implementations MUST put all rows that can be generated from the resource
records processed for the utypes marked with an exclamation mark there.
For the remaining utypes, rows should be provided if
convenient; they mostly concern test queries and other curation-type
information that, while unlikely to be useful to normal users, may be useful
to clients to, e.g., ascertain the continued operation of services before
exposing users to them.
Individual
ingestors
MAY choose to expose additional metadata using other utypes, provided
they are formed according to the rules in
section 5 (this rule is intended
to minimize the risk of later clashes).
In addition to the metadata listed in this specification,
metadata defined in future
IVOA-approved VOResource extensions MUST or SHOULD be present in
res_details as the extensions require it.
Name
Utype | Type | Description |
|---|
ivoid
vr:Resource.identifier | adql:VARCHAR(*) | The parent resource. |
cap_index
N/A | adql:SMALLINT | The index of the parent capability; if NULL the utype-value pair describes a member of the entire resource. |
detail_utype
N/A | adql:VARCHAR(*) | The utype of the member |
detail_value
N/A | adql:VARCHAR(*) | (atomic) value of the member |
The ivoid column should be an explicit foreign key into
resource. It is recommended to maintain indexes on
at least the columns
detail_utype and detail_value.
The following columns MUST be lowercased during ingestion:
ivoid, detail_utype. Clients are advised to
use the ivo_nocasematch function to search in
detail_value if the values have textual content.